Was ist Hyper-Threading in Prozessoren? Was ist Hyper-Threading in Intel-Prozessoren? Gleichzeitige Lösung verschiedener Probleme
Es gab eine Zeit, in der es notwendig war, die Speicherleistung im Kontext der Hyper-Threading-Technologie zu bewerten. Wir sind zu dem Schluss gekommen, dass sein Einfluss nicht immer positiv ist. Als ein Quantum freier Zeit auftauchte, bestand der Wunsch, die Forschung fortzusetzen und die laufenden Prozesse mit einer Genauigkeit von Maschinentaktzyklen und Bits zu betrachten Software eigene Entwicklung.
Plattform im Studium
Gegenstand der Experimente – ASUS-Laptop N750JK mit Prozessor Intel Core Prozessor i7-4700HQ. Taktfrequenz 2,4 GHz, erhöht im Intel Turbo Boost-Modus auf bis zu 3,4 GHz. Installiert 16 Gigabyte DDR3-1600 RAM (PC3-12800), Betrieb im Dual-Channel-Modus. Operationssystem - Microsoft Windows 8.1 64 Bit.Abb.1 Konfiguration der untersuchten Plattform.
Der Prozessor der untersuchten Plattform enthält 4 Kerne, die bei aktivierter Hyper-Threading-Technologie Hardwareunterstützung für 8 Threads oder logische Prozessoren bieten. Die Plattform-Firmware übermittelt diese Informationen Betriebssystemüber die ACPI-Tabelle MADT (Multiple APIC Description Table). Da die Plattform nur einen RAM-Controller enthält, gibt es keine SRAT-Tabelle (System Resource Affinity Table), die die Nähe von Prozessorkernen zu Speichercontrollern angibt. Offensichtlich handelt es sich bei dem untersuchten Laptop nicht um eine NUMA-Plattform, aber das Betriebssystem betrachtet es zum Zwecke der Vereinheitlichung als NUMA-System mit einer Domäne, wie durch die Zeile NUMA Nodes = 1 angezeigt. Eine Tatsache, die für uns von grundlegender Bedeutung ist Experimente zeigen, dass der Datencache der ersten Ebene für jeden der vier Kerne eine Größe von 32 Kilobyte hat. Zwei logische Prozessoren, die sich einen Kern teilen, teilen sich die L1- und L2-Caches.
Operation wird untersucht
Wir werden die Abhängigkeit der Lesegeschwindigkeit eines Datenblocks von seiner Größe untersuchen. Dazu wählen wir die produktivste Methode, nämlich das Lesen von 256-Bit-Operanden mit dem AVX-Befehl VMOVAPD. In den Diagrammen zeigt die X-Achse die Blockgröße und die Y-Achse die Lesegeschwindigkeit. Um Punkt X herum, der der Größe des L1-Cache entspricht, erwarten wir einen Wendepunkt, da die Leistung sinken sollte, nachdem der verarbeitete Block die Cache-Grenzen verlässt. In unserem Test arbeitet bei Multithread-Verarbeitung jeder der 16 initiierten Threads mit einem eigenen Adressbereich. Um die Hyper-Threading-Technologie innerhalb der Anwendung zu steuern, verwendet jeder Thread die API-Funktion SetThreadAffinityMask, die eine Maske festlegt, in der jedem logischen Prozessor ein Bit entspricht. Ein einzelner Bitwert ermöglicht die Verwendung des angegebenen Prozessors durch einen bestimmten Thread, ein Nullwert verhindert dies. Für 8 logische Prozessoren der untersuchten Plattform ermöglicht Maske 11111111b die Verwendung aller Prozessoren (Hyper-Threading ist aktiviert), Maske 01010101b ermöglicht die Verwendung eines logischen Prozessors in jedem Kern (Hyper-Threading ist deaktiviert).In den Grafiken werden folgende Abkürzungen verwendet:
MBPS (Megabyte pro Sekunde) – Blocklesegeschwindigkeit in Megabyte pro Sekunde;
CPI (Clocks per Instruction) – Anzahl der Taktzyklen pro Befehl;
TSC (Zeitstempelzähler) – CPU-Zykluszähler.
Hinweis: Beim Einlaufen stimmt die Taktrate des TSC-Registers möglicherweise nicht mit der Taktrate des Prozessors überein Turbo Modus Schub. Dies muss bei der Interpretation der Ergebnisse berücksichtigt werden.
Auf der rechten Seite der Diagramme wird ein hexadezimaler Dump der Anweisungen visualisiert, die den Schleifenkörper der Zieloperation bilden, die in jedem der Programmthreads ausgeführt wird, oder die ersten 128 Bytes dieses Codes.
Erleben Sie Nr. 1. Ein Thread

Abb.2 Einzelthread-Lesung
Die maximale Geschwindigkeit beträgt 213563 Megabyte pro Sekunde. Der Wendepunkt liegt bei einer Blockgröße von etwa 32 Kilobyte.
Erlebnis Nr. 2. 16 Threads auf 4 Prozessoren, Hyper-Threading deaktiviert

Abb. 3 Lesen in sechzehn Threads. Die Anzahl der verwendeten logischen Prozessoren beträgt vier
Hyper-Threading ist deaktiviert. Die maximale Geschwindigkeit beträgt 797598 Megabyte pro Sekunde. Der Wendepunkt liegt bei einer Blockgröße von etwa 32 Kilobyte. Wie erwartet erhöhte sich die Geschwindigkeit im Vergleich zum Lesen mit einem Thread um etwa das Vierfache, basierend auf der Anzahl der arbeitenden Kerne.
Erlebnis Nr. 3. 16 Threads auf 8 Prozessoren, Hyper-Threading aktiviert

Abb.4 Lesen in sechzehn Threads. Die Anzahl der verwendeten logischen Prozessoren beträgt acht
Hyper-Threading ist aktiviert. Die maximale Geschwindigkeit beträgt 800.722 Megabyte pro Sekunde; durch die Aktivierung von Hyper-Threading stieg sie fast nicht an. Der große Nachteil ist, dass der Wendepunkt bei einer Blockgröße von etwa 16 Kilobyte auftritt. Durch die Aktivierung von Hyper-Threading wurde die maximale Geschwindigkeit leicht erhöht, aber der Geschwindigkeitsabfall tritt jetzt bei der Hälfte der Blockgröße auf – etwa 16 Kilobyte, sodass die Durchschnittsgeschwindigkeit deutlich gesunken ist. Dies ist nicht überraschend, da jeder Kern über einen eigenen L1-Cache verfügt, während die logischen Prozessoren desselben Kerns ihn gemeinsam nutzen.
Schlussfolgerungen
Die untersuchte Operation lässt sich recht gut auf einem Mehrkernprozessor skalieren. Gründe: Jeder Kern enthält seinen eigenen L1- und L2-Cache, die Zielblockgröße ist vergleichbar mit der Cachegröße und jeder Thread arbeitet mit seinem eigenen Adressbereich. Für akademische Zwecke haben wir diese Bedingungen in einem synthetischen Test geschaffen, da wir erkannt haben, dass reale Anwendungen normalerweise weit von einer idealen Optimierung entfernt sind. Aber die Aktivierung von Hyper-Threading hatte selbst unter diesen Bedingungen negative Auswirkungen: Bei einer leichten Erhöhung der Spitzengeschwindigkeit kommt es zu einem erheblichen Verlust der Verarbeitungsgeschwindigkeit von Blöcken, deren Größe zwischen 16 und 32 Kilobyte liegt.In der Vergangenheit haben wir über die Simultaneous Multi-Threading (SMT)-Technologie gesprochen, die in verwendet wird Intel-Prozessoren. Und obwohl ursprünglich der Codename „Jackson Technology“ als mögliche Option angegeben wurde, kündigte Intel seine Technologie letzten Herbst auf dem IDF-Forum offiziell an. Der Codename Jackson wurde durch das passendere Hyper-Threading ersetzt. Um zu verstehen, wie die neue Technologie funktioniert, benötigen wir also einige Vorkenntnisse. Wir müssen nämlich wissen, was ein Thread ist und wie diese Threads ausgeführt werden. Warum funktioniert die Anwendung? Woher weiß der Prozessor, welche Operationen er mit welchen Daten durchführen soll? Alle diese Informationen sind im kompilierten Code der laufenden Anwendung enthalten. Und sobald die Anwendung einen Befehl oder Daten vom Benutzer empfängt, werden Threads sofort an den Prozessor gesendet, wodurch dieser als Reaktion auf die Anforderung des Benutzers ausführt, was er tun muss. Aus Sicht des Prozessors ist ein Thread eine Reihe von Anweisungen, die ausgeführt werden müssen. Wenn Sie in Quake III Arena von einem Projektil getroffen werden oder wenn Sie ein Dokument öffnen Microsoft Word Dem Prozessor werden bestimmte Anweisungen gesendet, die er ausführen muss.
Der Bearbeiter weiß genau, wo er diese Anweisungen erhalten kann. Zu diesem Zweck ist ein selten erwähntes Register namens Program Counter (PC) konzipiert. Dieses Register zeigt auf die Stelle im Speicher, an der der nächste auszuführende Befehl gespeichert ist. Wenn ein Thread an den Prozessor gesendet wird, wird die Speicheradresse des Threads in diesen Programmzähler geladen, sodass der Prozessor genau weiß, wo er mit der Ausführung beginnen muss. Nach jedem Befehl wird der Wert dieses Registers erhöht. Dieser gesamte Prozess läuft, bis der Thread beendet wird. Am Ende der Thread-Ausführung wird die Adresse in den Programmzähler eingetragen folgende Anweisungen, die abgeschlossen werden muss. Threads können sich gegenseitig unterbrechen, und der Prozessor speichert den Wert des Programmzählers auf dem Stapel und lädt einen neuen Wert in den Zähler. Allerdings gibt es bei diesem Prozess noch eine Einschränkung: Pro Zeiteinheit kann nur ein Thread ausgeführt werden.
Es gibt einen bekannten Weg, dieses Problem zu lösen. Es besteht darin, zwei Prozessoren zu verwenden – wenn ein Prozessor jeweils einen Thread ausführen kann, können zwei Prozessoren bereits zwei Threads in derselben Zeiteinheit ausführen. Beachten Sie, dass diese Methode nicht ideal ist. Es bringt viele andere Probleme mit sich. Einige sind Ihnen wahrscheinlich bereits bekannt. Erstens sind mehrere Prozessoren immer teurer als einer. Zweitens ist die Verwaltung zweier Prozessoren auch nicht so einfach. Vergessen Sie außerdem nicht die Aufteilung der Ressourcen zwischen den Prozessoren. Vor der Einführung des AMD 760MP-Chipsatzes teilten sich beispielsweise alle x86-Plattformen mit Multiprozessor-Unterstützung die gesamte Systembusbandbreite auf alle verfügbaren Prozessoren. Der Hauptnachteil ist jedoch ein anderer: Für solche Arbeiten müssen sowohl die Anwendung als auch das Betriebssystem selbst Multiprocessing unterstützen. Die Möglichkeit, die Ausführung mehrerer Threads auf Computerressourcen zu verteilen, wird oft als Multithreading bezeichnet. Gleichzeitig muss das Betriebssystem Multithreading unterstützen. Anwendungen müssen außerdem Multithreading unterstützen, um die Ressourcen Ihres Computers optimal zu nutzen. Bedenken Sie dies, wenn wir uns einen anderen Ansatz zur Lösung des Multithreading-Problems ansehen: neue Technologie Hyper-Threading von Intel.
Produktivität ist nie genug
Es wird immer viel über Effizienz gesprochen. Und das nicht nur im Unternehmensumfeld, bei einigen ernsthaften Projekten, sondern auch in Alltagsleben. Sie sagen, dass Homo Sapiens die Fähigkeiten ihres Gehirns nur teilweise nutzen. Gleiches gilt für die Prozessoren moderner Computer.
Nehmen wir zum Beispiel den Pentium 4. Der Prozessor verfügt über insgesamt sieben Ausführungseinheiten, von denen zwei mit der doppelten Geschwindigkeit von zwei Operationen (Micro-Ops) pro Taktzyklus arbeiten können. Aber auf jeden Fall würden Sie kein Programm finden, das alle diese Geräte mit Anweisungen füllen könnte. Herkömmliche Programme begnügen sich mit einfachen Ganzzahlberechnungen und einigen Operationen zum Laden und Speichern von Daten, während Gleitkommaoperationen außer Acht gelassen werden. Andere Programme (z. B. Maya) belasten hauptsächlich Gleitkomma-Geräte mit Arbeit.
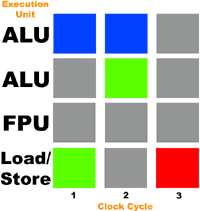
Um die Situation zu veranschaulichen, stellen wir uns einen Prozessor mit drei Ausführungseinheiten vor: einer arithmetischen Logikeinheit (Ganzzahl-ALU), einer Gleitkommaeinheit (FPU) und einer Lade-/Speichereinheit (zum Schreiben und Lesen von Daten aus dem Speicher). Nehmen wir außerdem an, dass unser Prozessor jede Operation in einem Taktzyklus ausführen und Operationen gleichzeitig auf alle drei Geräte verteilen kann. Stellen wir uns vor, dass ein Thread mit den folgenden Anweisungen zur Ausführung an diesen Prozessor gesendet wird:
Die folgende Abbildung veranschaulicht den Belastungsgrad der Aktoren (grau zeigt ein inaktives Gerät an, blau zeigt ein funktionierendes Gerät an):
Sie sehen also, dass in jedem Taktzyklus nur 33 % aller Aktoren genutzt werden. Diesmal bleibt die FPU komplett ungenutzt. Laut Intel nutzen die meisten IA-32 x86-Programme nicht mehr als 35 % der Ausführungseinheiten des Pentium 4-Prozessors.
Stellen wir uns einen anderen Thread vor und senden ihn zur Ausführung an den Prozessor. Diesmal besteht es aus den Vorgängen Laden von Daten, Hinzufügen und Speichern von Daten. Sie werden in der folgenden Reihenfolge ausgeführt:

Und auch hier beträgt die Belastung der Aktoren nur 33 %.
Ein guter Ausweg aus dieser Situation wäre Instruction Level Parallelism (ILP). In diesem Fall werden mehrere Anweisungen gleichzeitig ausgeführt, da der Prozessor in der Lage ist, mehrere parallele Ausführungseinheiten gleichzeitig zu füllen. Leider sind die meisten x86-Programme nicht ausreichend an ILP angepasst. Deshalb müssen wir andere Wege finden, um die Produktivität zu steigern. Wenn das System beispielsweise zwei Prozessoren gleichzeitig verwendet, könnten zwei Threads gleichzeitig ausgeführt werden. Diese Lösung wird Thread-Level-Parallelität (TLP) genannt. Diese Lösung ist übrigens recht teuer.
Welche anderen Möglichkeiten gibt es, die Exekutivgewalt zu stärken? moderne Prozessoren x86-Architektur?
Hyper-Threading
Das Problem der unzureichenden Auslastung von Aktoren hat mehrere Gründe. Im Allgemeinen gilt: Wenn der Prozessor Daten nicht mit der gewünschten Geschwindigkeit empfangen kann (dies liegt an einer unzureichenden Geschwindigkeit). Bandbreite Systembus und Speicherbus), dann werden die Aktoren nicht so effizient genutzt. Darüber hinaus gibt es noch einen weiteren Grund: die fehlende Parallelität auf Befehlsebene in den meisten Befehlsthreads.
Derzeit verbessern die meisten Hersteller die Geschwindigkeit von Prozessoren, indem sie die Taktrate und die Cache-Größe erhöhen. Natürlich kann man auf diese Weise die Leistung steigern, aber das Potenzial des Prozessors wird trotzdem nicht voll ausgeschöpft. Wenn wir mehrere Threads gleichzeitig ausführen könnten, könnten wir den Prozessor viel effizienter nutzen. Genau das ist die Essenz der Hyper-Threading-Technologie.
Hyper-Threading ist der Name einer Technologie, die es bisher außerhalb der x86-Welt gab: Simultaneous Multi-Threading (SMT). Die Idee hinter dieser Technologie ist einfach. Ein physischer Prozessor erscheint dem Betriebssystem als zwei logische Prozessoren, und das Betriebssystem erkennt den Unterschied zwischen einem SMT-Prozessor und zwei regulären Prozessoren nicht. In beiden Fällen leitet das Betriebssystem Threads weiter, als wäre es ein Dual-Prozessor-System. Darüber hinaus werden alle Probleme auf Hardwareebene gelöst.

In einem Prozessor mit Hyper-Threading verfügt jeder logische Prozessor über einen eigenen Registersatz (einschließlich eines separaten Programmzählers). Um die Technologie einfach zu halten, wird keine gleichzeitige Ausführung von Abruf-/Dekodierungsanweisungen in zwei Threads implementiert. Das heißt, solche Anweisungen werden einzeln ausgeführt. Es werden nur gewöhnliche Befehle parallel ausgeführt.
Die Technologie wurde letzten Herbst auf dem Intel Developer Forum offiziell angekündigt. Die Technologie wurde auf einem Xeon-Prozessor demonstriert, wobei das Rendering mit Maya durchgeführt wurde. In diesem Test schnitt der Xeon mit Hyper-Threading 30 % besser ab als der Standard-Xeon. Eine schöne Leistungssteigerung, aber das Interessanteste ist, dass die Technologie bereits in den Pentium 4- und Xeon-Kernen vorhanden ist, nur dass sie ausgeschaltet ist.
Die Technologie wurde noch nicht veröffentlicht, aber diejenigen unter Ihnen, die den 0,13-Mikrometer-Xeon gekauft und diesen Prozessor auf Platinen mit einem aktualisierten BIOS installiert haben, waren wahrscheinlich überrascht, eine Option im BIOS zum Aktivieren/Deaktivieren von Hyper-Threading zu sehen.
In der Zwischenzeit lässt Intel die Hyper-Threading-Option standardmäßig deaktiviert. Um es zu aktivieren, müssen Sie jedoch lediglich das BIOS aktualisieren. All dies gilt für Workstations und Server, was ist mit dem Markt? persönliche Computer, das Unternehmen hat in naher Zukunft keine Pläne für diese Technologie. Obwohl es möglich ist, bieten Motherboard-Hersteller die Möglichkeit, Hyper-Threading mithilfe eines speziellen BIOS zu aktivieren.
Es bleibt sehr Interesse Fragen Warum möchte Intel diese Option deaktiviert lassen?
Tiefer in die Technologie eintauchen
Erinnern Sie sich an die beiden Threads aus den vorherigen Beispielen? Nehmen wir dieses Mal an, dass unser Prozessor mit Hyper-Threading ausgestattet ist. Mal sehen, was passiert, wenn wir versuchen, diese beiden Threads gleichzeitig auszuführen:

Wie zuvor zeigen blaue Rechtecke die Ausführung der Anweisung des ersten Threads an, und grüne Rechtecke zeigen die Ausführung der Anweisung des zweiten Threads an. Graue Rechtecke zeigen ungenutzte Ausführungsgeräte und rote Rechtecke weisen auf einen Konflikt hin, wenn zwei verschiedene Anweisungen aus verschiedenen Threads am selben Gerät ankommen.
Was sehen wir also? Die Parallelität auf Thread-Ebene schlug fehl – die Ausführungsgeräte wurden noch weniger effizient genutzt. Anstatt Threads parallel auszuführen, führt der Prozessor sie langsamer aus, als wenn er sie ohne Hyper-Threading ausführen würde. Der Grund ist ganz einfach. Wir haben versucht, zwei sehr ähnliche Threads gleichzeitig auszuführen. Schließlich bestehen beide aus Lade-/Speicheroperationen und Additionsoperationen. Wenn wir eine „Ganzzahl“-Anwendung und eine Gleitkomma-Anwendung parallel ausführen würden, wären wir in einer viel besseren Situation. Wie Sie sehen, hängt die Wirksamkeit von Hyper-Threading stark von der Art der Belastung des PCs ab.
Derzeit nutzen die meisten PC-Benutzer ihren Computer ungefähr so, wie in unserem Beispiel beschrieben. Der Prozessor führt viele sehr ähnliche Vorgänge aus. Leider treten bei ähnlichen Vorgängen zusätzliche Managementschwierigkeiten auf. Es gibt Situationen, in denen keine Aktoren des benötigten Typs mehr vorhanden sind und es glücklicherweise doppelt so viele Anweisungen wie üblich gibt. Wenn die Prozessoren von Heimcomputern die Hyper-Threading-Technologie verwenden würden, gäbe es in den meisten Fällen keine Leistungssteigerung, vielleicht sogar einen Rückgang von 0–10 %.
Auf Workstations bietet Hyper-Threading jedoch mehr Möglichkeiten, die Produktivität zu steigern. Andererseits kommt es aber auch auf die konkrete Nutzung des Computers an. Eine Workstation kann entweder ein High-End-Computer zur Verarbeitung von 3D-Grafiken oder einfach ein stark ausgelasteter Computer sein.
Die größte Leistungssteigerung durch die Verwendung von Hyper-Threading wird in beobachtet Serveranwendungen. Dies ist vor allem auf die große Vielfalt der an den Prozessor gesendeten Operationen zurückzuführen. Ein Datenbankserver, der Transaktionen verwendet, kann 20–30 % schneller laufen, wenn die Hyper-Threading-Option aktiviert ist. Etwas geringere Leistungssteigerungen sind auf Webservern und in anderen Bereichen zu beobachten.
Maximale Effizienz durch Hyper-Threading
Glauben Sie, dass Intel Hyper-Threading nur für seine Serverprozessorreihe entwickelt hat? Natürlich nicht. Wenn das der Fall wäre, würden sie den Chipplatz nicht auf ihren anderen Prozessoren verschwenden. Tatsächlich eignet sich die im Pentium 4 und Xeon verwendete NetBurst-Architektur perfekt für einen Kernel, der gleichzeitiges Multithreading unterstützt. Stellen wir uns noch einmal den Prozessor vor. Dieses Mal wird es einen weiteren Aktor haben – ein zweites Ganzzahlgerät. Schauen wir uns an, was passiert, wenn Threads von beiden Geräten ausgeführt werden:
Bei Verwendung des zweiten ganzzahligen Geräts trat der einzige Konflikt beim letzten Vorgang auf. Unser theoretischer Prozessor ähnelt in gewisser Weise dem Pentium 4. Er verfügt über bis zu drei Integer-Geräte (zwei ALUs und ein langsames Integer-Gerät für rotierende Schichten). Noch wichtiger ist, dass beide Pentium-4-Integer-Geräte mit doppelter Geschwindigkeit laufen können und zwei Mikrooperationen pro Taktzyklus ausführen. Dies wiederum bedeutet, dass jedes dieser beiden Pentium 4/Xeon-Integer-Geräte diese beiden Additionsoperationen von verschiedenen Threads in einem Taktzyklus ausführen könnte.
Aber das löst unser Problem nicht. Es würde wenig Sinn machen, dem Prozessor einfach zusätzliche Ausführungseinheiten hinzuzufügen, um die Leistung von Hyper-Threading zu steigern. Bezogen auf den Siliziumplatz wäre dies extrem teuer. Stattdessen schlug Intel den Entwicklern vor, Programme für Hyper-Threading zu optimieren.
Mit der HALT-Anweisung können Sie einen der logischen Prozessoren anhalten und so die Leistung von Anwendungen steigern, die nicht von Hyper-Threading profitieren. Die Anwendung wird also nicht langsamer ausgeführt, sondern einer der logischen Prozessoren wird angehalten und das System läuft auf einem logischen Prozessor – die Leistung ist dieselbe wie bei Computern mit einem Prozessor. Wenn die Anwendung dann entscheidet, dass sie von der Hyper-Threading-Leistung profitiert, nimmt der zweite logische Prozessor einfach seine Arbeit wieder auf.
Auf der Intel-Website gibt es eine Präsentation, die genau beschreibt, wie man programmiert, um das Beste aus Hyper-Threading herauszuholen.
Schlussfolgerungen
Obwohl wir alle sehr aufgeregt waren, als wir Gerüchte über Hyper-Threading in den Kernen aller modernen Pentium 4/Xeons hörten, wird es dennoch nicht für alle Fälle kostenlose Leistung geben. Die Gründe liegen auf der Hand und die Technologie hat noch einen langen Weg vor sich, bevor Hyper-Threading auf allen Plattformen, einschließlich Heimcomputern, zum Einsatz kommt. Und mit der Unterstützung der Entwickler kann die Technologie definitiv ein guter Verbündeter für Pentium 4, Xeon und Prozessoren der nächsten Generation von Intel sein.
Angesichts der aktuellen Einschränkungen und der verfügbaren Verpackungstechnologie scheint Hyper-Threading eine intelligentere Wahl für den Verbrauchermarkt zu sein als beispielsweise AMDs SledgeHammer-Ansatz – diese Prozessoren verwenden bis zu zwei Kerne. Und bis Verpackungstechnologien wie Bumpless Build-Up Layer ausgereift sind, können die Kosten für die Entwicklung von Multicore-Prozessoren unerschwinglich sein.
Es ist interessant zu beobachten, wie unterschiedlich sich AMD und Intel in den letzten Jahren entwickelt haben. Schließlich hat AMD einst praktisch Intel-Prozessoren kopiert. Mittlerweile haben Unternehmen grundlegend unterschiedliche Ansätze für zukünftige Prozessoren für Server und Workstations entwickelt. AMD hat wirklich großartige Arbeit geleistet ein langer Weg. Und wenn Sledge Hammer-Prozessoren tatsächlich zwei Kerne verwenden, ist eine solche Lösung leistungseffizienter als Hyper-Threading. Tatsächlich werden in diesem Fall nicht nur die Anzahl aller Aktuatoren verdoppelt, sondern auch die oben beschriebenen Probleme beseitigt.
Hyper-Threading wird den Mainstream-PC-Markt noch eine Weile nicht erreichen, aber mit guter Entwicklerunterstützung könnte es die nächste Technologie sein, die von der Serverebene auf Mainstream-PCs vordringt.
Wird Hyper-Threading genannt.
Terminologie
Die Terminologie in der Technologiewelt kann verwirrend und leicht zu verstehen sein
ist vergessen, also beginnen wir mit der Klärung der Bedeutung der Begriffe,
die ich hier verwenden werde. Man spricht von einem Mehrkernprozessor
ein Prozessor, der mehr als einen Kern auf einem einzigen integrierten Schaltkreis enthält.
Multi-Chip bedeutet, dass mehrere Chips miteinander kombiniert werden.
Multiprozessor bedeutet, dass mehrere separate Prozessoren zusammenarbeiten
im selben System arbeiten. Und natürlich bedeutet CPU zentral
ein Prozessor mit einem oder mehreren Kernen, von denen jeder hat
Ausführungsgerät (von dem aus die gesamte Mathematik ausgeführt wird).
Hyper-Threading
Was ist also Hyper-Threading-Technologie? Der Begriff Hyper-Threading
gebraucht von Intel um ihre Technologie zu bestimmen, welche
ermöglicht es dem Betriebssystem, einen CPU-Kern als zwei Kerne zu behandeln.
Somit funktioniert das Betriebssystem mit einem solchen Kernel genauso wie mit
Jeder Multi-Core-Chip sendet mehrere
Prozesse. Obwohl es mit dieser Technologie möglich ist, das System zu erzwingen
Nehmen Sie einen Kern als drei oder mehr Kerne wahr, architektonische Komplexität
hat Intel auf die Veröffentlichung von Hyper-Threaded-Kernen beschränkt, die dies können
als nur zwei Kerne wahrgenommen werden.
Hier gibt es keinen Trick. Intel hat eine Architektur entwickelt
Chip zur Verarbeitung von Prozessen auf die gleiche Weise wie Multi-Core-Chips
Prozessoren. Im Wesentlichen hat Intel stark genutzte Duplikate verwendet
Bereiche des CPU-Kerns und stellte sicher, dass diese Abschnitte von mehreren genutzt wurden
Prozesse gleichzeitig. Weil diese Kernregionen getrennt sind
(Sie befinden sich auf demselben Chip, nutzen aber unterschiedliche Bereiche
In diesem Kristall stören sich diese Prozesse nicht gegenseitig. Solch
Hyper-Threading-kompatible Kernel sind nicht ganz dasselbe
das meiste Multi-Core-Prozessoren; Nicht jeder Prozess kann gleichzeitig ausgeführt werden
Um mit einem anderen Prozess ausgeführt zu werden, muss ein separater Teil verwendet werden
Kernel für ihre Operationen.
Hyper-Threading ist ein Beispiel für Simultaneous
Multithreading (Simultanes Multi-Threading – SMT). SMT ist eines davon
von zwei Arten von Multithreading. Der andere Typ wird als temporär bezeichnet
Multithreading (Temporal Multi-Threading – TMT). Mit TMT-Kern
Der Prozessor führt Anweisungen zuerst von einem Thread aus, dann von
eine andere und dann noch einmal von der ersten, und daher kommt es dem Benutzer so vor
zwei Threads laufen gleichzeitig, obwohl sich die Threads in Wirklichkeit einfach teilen
CPU-Zeit untereinander. Mit SMT können Anweisungen von jedem Thread
gleichzeitig ausgeführt werden. Diese Technologien können verwendet werden für
Produktivität erhöhen.
Benutzer sollten sich auch darüber im Klaren sein, dass nicht alle Betriebssysteme dies unterstützen
Hyper-Threading-Technologie. Laut Intel sind die folgenden Betriebssysteme von
Microsoft ist vollständig auf die Unterstützung der Technologie optimiert
Hyper-Threading:
Microsoft Windows XP Professional Edition
Microsoft Windows XP Home Edition
Microsoft Windows Vista Startseite Basic
Microsoft Windows Vista Home Premium
Microsoft Windows Vista Home Ultimate
Microsoft Windows Vista Home Business
Und wie Intel sagt, sind die folgenden Betriebssysteme nicht vollständig
optimiert für die Hyper-Threading-Technologie und daher dies
Die Technologie muss in den BIOS-Einstellungen deaktiviert werden:
Microsoft Windows 2000 (alle Versionen)
Microsoft Windows NT 4.0
Microsoft Windows ME
Microsoft Windows 98
Microsoft Windows 98 SE
Manchmal Anwendungen wie Firefox
Es gibt Probleme mit Hyper-Threading. Der beste Weg Lösungen hierfür
Das Problem besteht darin, dass die Anwendung im Windows 98-Kompatibilitätsmodus ausgeführt wird.
Klicken Sie dazu mit der rechten Maustaste auf das Anwendungssymbol.
Gehen Sie zu den Eigenschaften, wählen Sie Kompatibilität und aktivieren Sie das Kontrollkästchen
„Führen Sie dieses Programm aus
Kompatibilitätsmodus)“ und wählen Sie Windows 98 aus. Dadurch wird die Technologie deaktiviert
Hyper-Threading für Diese Anwendung, da Windows 98 dies nicht tut
unterstützt Hyper-Threading.
Vorteile von Hyper-Threading
Es gibt viele Vorteile von Hyper-Threading. Intel-Unternehmen
gibt an, dass es zu Duplikaten kommt bestimmte Bereiche Der CPU-Kern erhöht sich
Kerngröße um etwa 5 Prozent, sorgt aber immer noch für eine Steigerung
Leistung um 30 Prozent im Vergleich zu anderen baugleichen Produkten
Prozessorkerne ohne Hyper-Threading.
Nachteile von Hyper-Threading
Werbung
//
//]]-->

Obwohl Hyper-Threaded-CPU-Kerne nicht die volle Kapazität bieten
Vorteile von Multi-Core-Prozessoren haben sie immer noch erheblich
Vorteile gegenüber herkömmlichen Single-Core-Prozessoren. Sicherlich,
Es ist immer nützlich zu wissen, welche Nachteile die Technologie mit sich bringt,
bevor Sie es verwenden. Ein Nachteil vieler Anwendungen ist
hohes Niveau Energieverbrauch. Da alle Bereiche des Kernels benötigt werden
in Leistung (auch im Standby-Modus), Gesamtenergieverbrauch
Hyper-Threading-Kerne sowie alle oben genannten Kerne mit SMT-Unterstützung. Ohne
die angebotenen Geschwindigkeitsverbesserungen optimal nutzen
Bei einem Hyper-Thread-Kernel wird es einfach der Kernel sein, der mehr verbraucht
Elektrizität. Für viele Situationen, einschließlich Serverfarmen und Mobilgeräte
Bei Computern ist ein solch erhöhter Stromverbrauch unerwünscht.
Darüber hinaus vergleichen wir einen Hyper-Threaded-CPU-Kern mit einem Nicht-Hyper-Threaded-CPU-Kern
Im Kernel werden Sie einen deutlichen Anstieg des Cache-Überlaufs feststellen. ARM
gibt an, dass dieser Anstieg bis zu 42 % betragen könnte. Vergleichen Sie dies
Wert bei Multi-Core-Prozessoren, bei denen der Cache-Überlauf um reduziert wird
37 %, und das wird wirklich wichtig werden.
Nachdem Sie nun die Informationen über all diese Nachteile gelesen haben, werden Sie,
Sie könnten zu dem Schluss kommen, dass diese Hyper-Threaded-Kernel nutzlos sind. Und du hast recht, in
einige Situationen. Zum Beispiel, wenn der Stromverbrauch im Vordergrund steht
Aspekt in Ihrer Situation, dann Hyper-Threaded-Kernel (oder andere Kernel).
mit SMT-Unterstützung) unerwünscht sein. Allerdings auch beim Verbrauch
Leistung steht ganz oben auf Ihrer Anforderungsliste, Hyper-Threaded-Kerne
könnte eine passende Option sein. Nehmen wir als Beispiel eine Serverfarm.
Normalerweise beträgt der Energieverbrauch von Serverfarmen (diese).
Rechnungen können mehrere tausend Dollar pro Monat betragen!). Allerdings in
In heutigen Serverfarmen sind viele Server virtuell.
Es kann also durchaus sein, dass Sie mehrere haben Virtuelle Server
auf einem physischen Server, mit Leistungsanforderungen
Diese Server sind nicht überdurchschnittlich. Es ist durchaus möglich, dass dieser Typ
Die Konfiguration gewährleistet eine ausreichende CPU-Auslastung
die maximale Leistung von Hyper-Threaded-Kernen nutzen,
Gleichzeitig wird der Energieverbrauch auf ein Minimum reduziert.
Wie immer ist es wichtig, vorher alle Betriebsumstände klar zu bedenken
als sich für den Einsatz von Technologie zu entscheiden. Technologien ohne Nachteile
kommt praktisch nie vor. Im Allgemeinen nützlich oder nutzlos
Es wird lediglich eine bestimmte Technologie in Bezug auf Ihre Situation offenbart
nach einer gründlichen Prüfung aller Vor- und Nachteile.
Hyper-Threading ist nur eine Technologie. Für weitere
Für Informationen zu diesem Thema empfehle ich die Lektüre meiner beiden vorherigen Artikel. Zunächst ein Artikel zu , der erklärt, wie Multi-Core-Prozessoren auf den Cache-Speicher zugreifen. Zweitens mein Artikel zur Prozessoraffinität.
Hier geht es um die Interaktion zwischen Anwendungen und
mehrere Kerne. Wenn Sie Fragen zu meinem Artikel haben,
Schicken Sie mir diese per E-Mail und ich werde versuchen, so schnell wie möglich zu antworten.
Russell
Hitchcock (Russell Hitchcock) fungiert als Berater und ist verantwortlich für
inklusive Netzwerk Hardware(vernetzte Hardware), Steuerung
Systeme und Antennen. Russell schreibt auch technische Artikel zu verschiedenen Themen
Viele Intel-Prozessoren enthalten Module, die die Hyper-Threading-Technologie unterstützen, was nach der Idee der Entwickler dazu beitragen soll, die Leistung des Chips zu steigern und den PC insgesamt zu beschleunigen. Was sind die Besonderheiten dieser Lösung eines amerikanischen Konzerns? Wie können Sie Hyper-Threading nutzen?
Technologiegrundlagen
Schauen wir uns einige wichtige Informationen zum Thema Hyper-Threading an. Was ist das für eine Technologie? Es wurde von Intel entwickelt und erstmals 2001 der Öffentlichkeit vorgestellt. Der Zweck seiner Erstellung bestand darin, die Serverleistung zu steigern. Das beim Hyper-Threading implementierte Hauptprinzip ist die Verteilung der Prozessorberechnungen auf mehrere Threads. Darüber hinaus ist dies auch dann möglich, wenn nur ein Kern auf dem entsprechenden Chiptyp installiert ist (wenn wiederum zwei oder mehr davon vorhanden sind und die Threads im Prozessor bereits verteilt sind, ergänzt die Technologie diesen Mechanismus erfolgreich).
Die Sicherstellung des Betriebs des Haupt-PC-Chips innerhalb mehrerer Threads erfolgt durch die Erstellung von Kopien der Architekturzustände bei Berechnungen. Dabei werden die gleichen Ressourcen auf dem Chip verwendet. Wenn die Anwendung die entsprechende Funktion verwendet, werden praktisch wichtige Vorgänge viel schneller ausgeführt. Wichtig ist auch, um welche Technik es sich handelt wir reden über, unterstützt vom Ein-/Ausgabesystem des Computers – BIOS.
Hyper-Threading aktivieren
Sofern der im PC verbaute Prozessor den entsprechenden Standard unterstützt, wird dieser in der Regel automatisch aktiviert. In manchen Fällen müssen Sie dies jedoch manuell tun notwendige Maßnahmen damit die Hyper-Threading-Technologie funktioniert. Wie aktiviere ich es? Sehr einfach.
Sie müssen die Haupt-BIOS-Schnittstelle aufrufen. Dazu müssen Sie gleich zu Beginn des Computerstarts die Entf-Taste drücken, manchmal F2, F10, seltener auch andere Tasten, aber die gewünschte Taste erscheint immer in einer der Textzeilen, die unmittelbar nach dem Einschalten auf dem Bildschirm angezeigt werden den PC. In der BIOS-Schnittstelle müssen Sie das Hyper-Threading-Element finden: In Versionen des I/O-Systems, die es unterstützen, befindet es sich normalerweise an prominenter Stelle. Nachdem Sie die entsprechende Option ausgewählt haben, drücken Sie die Eingabetaste, aktivieren Sie sie und markieren Sie sie als Aktiviert. Wenn diesen Modus bereits angegeben ist, dann funktioniert die Hyper-Threading-Technologie. Sie können alle Vorteile nutzen. Nachdem Sie die Technologie in den Einstellungen aktiviert haben, sollten Sie alle Einträge im BIOS speichern, indem Sie Save and Exit Setup wählen. Danach wird der Computer in einem Modus neu gestartet, in dem der Prozessor mit Hyper-Theading-Unterstützung läuft. Hyper-Threading wird auf ähnliche Weise deaktiviert. Dazu müssen Sie im entsprechenden Punkt eine andere Option auswählen – Deaktiviert – und die Einstellungen speichern.
Nachdem Sie gelernt haben, wie Sie Hyper-Threading aktivieren und deaktivieren diese Technologie Schauen wir uns die Funktionen genauer an.
Prozessoren mit Hyper-Threading-Unterstützung
Der erste Prozessor, auf dem das betreffende Konzept des Unternehmens umgesetzt wurde, war einigen Quellen zufolge der Intel Xeon MP, auch bekannt als Foster MP. Dieser Chip ähnelt in einigen architektonischen Komponenten dem Pentium 4, auf dem die betreffende Technologie ebenfalls nachträglich implementiert wurde. Anschließend wurde die Multithread-Computing-Funktion implementiert Serverprozessoren Xeon mit Prestonia-Kern.

Wenn wir über die aktuelle Verbreitung von Hyper-Threading sprechen, welche „Prozessoren“ unterstützen es? Zu den beliebtesten Mikroschaltungen dieser Art- diejenigen, die zu den Core- und Xeon-Familien gehören. Es gibt auch Informationen, dass ähnliche Algorithmen in Itanium- und Atom-Prozessoren implementiert sind.
Nachdem wir die grundlegenden Informationen über Hyper-Threading und die es unterstützenden Prozessoren untersucht haben, werden wir die bemerkenswertesten Fakten zur Entwicklungsgeschichte der Technologie betrachten.
Entwicklungsgeschichte
Wie oben erwähnt, stellte Intel das betreffende Konzept im Jahr 2001 der Öffentlichkeit vor. Die ersten Schritte zur Entwicklung der Technologie wurden jedoch bereits Anfang der 90er Jahre unternommen. Ingenieure Amerikanisches Unternehmen Es wurde festgestellt, dass die Ressourcen der PC-Prozessoren bei der Ausführung einer Reihe von Vorgängen nicht vollständig genutzt werden.
Wie Intel-Experten berechnet haben, wird der Chip während der Arbeit am PC über längere Zeiträume – fast die meiste Zeit – von etwa 30 % nicht sehr aktiv genutzt. Die Meinungen der Experten zu dieser Zahl gehen sehr auseinander – manche halten sie für deutlich unterschätzt, andere stimmen der These der amerikanischen Entwickler voll und ganz zu.

Die meisten IT-Spezialisten waren sich jedoch einig, dass zwar nicht 70 % der Prozessorkapazität im Leerlauf sind, dies aber eine sehr erhebliche Menge ist.
Die Hauptaufgabe der Entwickler
Intel hat beschlossen, diesen Zustand durch einen qualitativ neuen Ansatz zur Sicherstellung der Effizienz der wichtigsten PC-Chips zu korrigieren. Es wurde vorgeschlagen, eine Technologie zu entwickeln, die eine aktivere Nutzung der Prozessorfunktionen ermöglichen würde. 1996 begannen Intel-Spezialisten mit der praktischen Entwicklung.
Nach dem Konzept des amerikanischen Unternehmens könnte der Prozessor bei der Verarbeitung von Daten aus einem Programm ungenutzte Ressourcen für die Arbeit mit einer anderen Anwendung (oder einer Komponente der aktuellen Anwendung, die jedoch eine andere Struktur aufweist und den Einsatz zusätzlicher Ressourcen erfordert) lenken. . Der entsprechende Algorithmus ging auch von einer effektiven Interaktion mit anderen PC-Hardwarekomponenten aus – RAM, Chipsatz, sowie Programme.
Intel hat es geschafft, das Problem zu lösen. Die Technologie hieß ursprünglich Willamette. Im Jahr 1999 wurde es in die Architektur einiger Prozessoren eingeführt und mit den Tests begonnen. Bald erhielt die Technologie ihren modernen Namen – Hyper-Threading. Es ist schwer zu sagen, was genau es war – ein einfaches Rebranding oder radikale Anpassungen der Plattform. Weitere Fakten zum Auftreten von Technologie in der Öffentlichkeit und ihrer Umsetzung in verschiedene Modelle Intel-Prozessoren wissen wir bereits. Zu den heute gebräuchlichen Entwicklungsnamen gehört Hyper-Threading-Technologie.
Überlegungen zur Technologiekompatibilität
Wie gut ist die Unterstützung der Hyper-Threading-Technologie in Betriebssystemen implementiert? Es kann angemerkt werden, dass, wenn wir über moderne sprechen Windows-Versionen Dann wird es keine Probleme geben, wenn der Benutzer die Vorteile der Intel Hyper-Threading-Technologie voll ausnutzt. Natürlich ist es auch sehr wichtig, dass die Technologie vom Ein-/Ausgabesystem unterstützt wird – das haben wir oben gesagt.
Software- und Hardwarefaktoren
Bezüglich älterer Betriebssystemversionen – Windows 98, NT und das relativ veraltete XP – notwendige Bedingung Hyper-Threading-Kompatibilität – ACPI-Unterstützung. Wenn es nicht im Betriebssystem implementiert ist, werden nicht alle Berechnungsthreads, die von den entsprechenden Modulen gebildet werden, vom Computer erkannt. Beachten Sie, dass Windows XP insgesamt die Nutzung der Vorteile der jeweiligen Technologie gewährleistet. Es ist außerdem äußerst wünschenswert, dass Multithreading-Algorithmen in Anwendungen implementiert werden, die vom PC-Besitzer verwendet werden.
Manchmal kann ein PC erforderlich sein – wenn darauf Prozessoren mit Hyper-Threading-Unterstützung installiert sind, statt derer, die ursprünglich darauf installiert waren und nicht mit der Technologie kompatibel waren. Allerdings wird es wie bei Betriebssystemen keine besonderen Probleme geben, wenn dem Nutzer ein moderner PC zur Verfügung steht oder zumindest einer, der den Hardwarekomponenten der ersten Hyper-Threading-Prozessoren entspricht, wie oben erwähnt, implementiert in Die Core-Linie und daran angepasste Chipsätze auf Motherboards unterstützen die entsprechenden Funktionen des Chips vollständig.

Beschleunigungskriterien
Wenn der Computer auf der Ebene der Hardware- und Softwarekomponenten nicht mit Hyper-Threading kompatibel ist, kann diese Technologie theoretisch sogar seinen Betrieb verlangsamen. Dieser Sachverhalt hat dazu geführt, dass einige IT-Spezialisten an den Erfolgsaussichten der Intel-Lösung zweifeln. Sie entschieden, dass es sich nicht um einen Technologiesprung handelte, sondern um einen Marketingtrick, der dem Konzept des Hyper-Threadings zugrunde liegt, das aufgrund seiner Architektur nicht in der Lage ist, einen PC wesentlich zu beschleunigen. Doch die Zweifel der Kritiker wurden von den Intel-Ingenieuren schnell ausgeräumt.
Die Grundvoraussetzungen für den erfolgreichen Einsatz der Technologie sind also:
Hyper-Threading-Unterstützung durch das I/O-System;
Kompatibilität Hauptplatine mit einem Prozessor des entsprechenden Typs;
Technologieunterstützung durch das Betriebssystem und die darin ausgeführte spezifische Anwendung.
Sollte es bei den ersten beiden Punkten keine besonderen Probleme geben, kann es hinsichtlich der Programmkompatibilität mit Hyper-Threading dennoch zu Problemen kommen. Es kann jedoch festgestellt werden, dass eine Anwendung, die beispielsweise die Arbeit mit Dual-Core-Prozessoren unterstützt, nahezu garantiert mit der Technologie von Intel kompatibel ist.

Zumindest gibt es Studien, die eine Leistungssteigerung von an Dual-Core-Chips angepassten Programmen um ca. 15-18 % belegen, wenn auf dem Prozessor Intel Hyper Threading-Module laufen. Wir wissen bereits, wie man sie deaktiviert (falls der Benutzer Zweifel an der Zweckmäßigkeit der Verwendung der Technologie hat). Aber es gibt wahrscheinlich nur sehr wenige greifbare Gründe für ihr Erscheinen.
Praktischer Nutzen von Hyper-Threading
Hat die betreffende Technologie für Intel einen spürbaren Unterschied gemacht? Hierzu gibt es unterschiedliche Meinungen. Viele bemerken jedoch, dass die Hyper-Threading-Technologie so beliebt geworden ist, dass diese Lösung für viele Hersteller von Serversystemen unverzichtbar geworden ist und auch von normalen PC-Benutzern positiv aufgenommen wurde.
Hardware-Verarbeitung
Der Hauptvorteil der Technologie besteht darin, dass sie im Hardwareformat implementiert ist. Das heißt, der Großteil der Berechnungen wird innerhalb des Prozessors auf speziellen Modulen durchgeführt und nicht in Form von Softwarealgorithmen, die auf die Ebene des Hauptkerns des Chips übertragen werden – was eine Reduzierung bedeuten würde Gesamtleistung PC. Wie IT-Experten anmerken, ist es den Intel-Ingenieuren im Allgemeinen gelungen, das Problem zu lösen, das sie zu Beginn der Entwicklung der Technologie identifiziert hatten – den Prozessor effizienter zu machen. Tatsächlich hat der Einsatz von Hyper-Threading, wie Tests gezeigt haben, bei der Lösung vieler für den Anwender praktisch bedeutsamer Probleme die Arbeit deutlich beschleunigt.

Es ist festzuhalten, dass unter den 4 Mikroschaltungen diejenigen Mikroschaltungen, die mit Modulen zur Unterstützung der betreffenden Technologie ausgestattet waren, deutlich effizienter arbeiteten als die ersten Modifikationen. Dies drückte sich vor allem in der Fähigkeit des PCs aus, im echten Multitasking-Modus zu funktionieren – wenn mehrere verschiedene Arten von Windows-Anwendungen, und es ist äußerst unerwünscht, dass aufgrund des erhöhten Verbrauchs von Systemressourcen durch einen von ihnen die Geschwindigkeit der anderen abnimmt.
Gleichzeitige Lösung verschiedener Probleme
Somit sind Prozessoren, die Hyper-Threading unterstützen, besser geeignet als Chips, die nicht damit kompatibel sind, um beispielsweise gleichzeitig einen Browser auszuführen, Musik abzuspielen und mit Dokumenten zu arbeiten. Alle diese Vorteile kommen für den Anwender in der Praxis natürlich nur dann zum Tragen, wenn die Soft- und Hardwarekomponenten des PCs ausreichend mit dieser Betriebsart kompatibel sind.
Ähnliche Entwicklungen
Die Hyper-Threading-Technologie ist nicht die einzige, die entwickelt wurde, um die PC-Leistung durch Multithread-Computing zu verbessern. Es hat Analoga.
Beispielsweise unterstützen die von IBM veröffentlichten POWER5-Prozessoren auch Multithreading. Das heißt, jeder von ihnen (insgesamt sind 2 entsprechende Elemente darauf installiert) kann Aufgaben innerhalb von 2 Threads ausführen. Somit verarbeitet der Chip 4 Rechenthreads gleichzeitig.

AMD hat es auch hervorragende Ergebnisse Arbeiten im Bereich Multithreading-Konzepte. Daher ist bekannt, dass die Bulldozer-Architektur Algorithmen verwendet, die dem Hyper-Threading ähneln. Die Besonderheit der AMD-Lösung besteht darin, dass jeder Thread separate Prozessorblöcke verarbeitet. Die zweite Ebene bleibt allgemein. Ähnliche Konzepte sind in AMDs Bobcat-Architektur umgesetzt, die auf Laptops und kleine PCs zugeschnitten ist.
Natürlich können die Konzepte von AMD, IBM und Intel sehr bedingt als direkte Analoga betrachtet werden. Sowie Ansätze zum Entwurf der Prozessorarchitektur im Allgemeinen. Die in den entsprechenden Technologien umgesetzten Prinzipien können jedoch als recht ähnlich angesehen werden, und die von den Entwicklern gesetzten Ziele im Hinblick auf die Steigerung der Effizienz von Mikroschaltungen können im Wesentlichen sehr ähnlich, wenn nicht sogar identisch sein.
Das sind die wichtigsten Fakten zur interessantesten Technologie von Intel. Wir haben herausgefunden, was es ist, wie man Hyper-Threading aktiviert oder umgekehrt deaktiviert. Das Problem ist wahrscheinlich praktischer Nutzen seine Vorteile, die genutzt werden können, indem sichergestellt wird, dass die Hardware des PCs und Softwarekomponenten unterstützt Technologie.
15.03.2013
Die Hyper-Threading-Technologie erschien erschreckenderweise schon vor mehr als 10 Jahren in Intel-Prozessoren. Und in dieser Moment Es ist ein wichtiges Element von Core-Prozessoren. Allerdings ist die Frage nach der Notwendigkeit von HT in Spielen noch nicht ganz geklärt. Wir haben uns entschieden, einen Test durchzuführen, um herauszufinden, ob Gamer einen Core i7 benötigen oder ob ein Core i5 besser ist. Und finden Sie auch heraus, wie viel besser der Core i3 als der Pentium ist.
Die von Intel entwickelte und ausschließlich in den Prozessoren des Unternehmens eingesetzte Hyper-Threading-Technologie, beginnend mit dem denkwürdigen Pentium 4, ist derzeit eine Selbstverständlichkeit. Eine beträchtliche Anzahl von Prozessoren aktueller und früherer Generationen ist damit ausgestattet. Es wird in naher Zukunft zum Einsatz kommen.
Und man muss zugeben, dass die Hyper-Threading-Technologie nützlich ist und sich positiv auf die Leistung auswirkt, sonst würde Intel sie nicht nutzen, um seine Prozessoren innerhalb der Linie zu positionieren. Und zwar nicht als zweitrangiges Element, sondern als eines der wichtigsten, wenn nicht sogar das wichtigste. Um zu verdeutlichen, wovon wir sprechen, haben wir eine Tabelle erstellt, die eine einfache Bewertung des Segmentierungsprinzips von Intel-Prozessoren ermöglicht.

Wie Sie sehen, gibt es kaum Unterschiede zwischen Pentium und Core i3 sowie zwischen Core i5 und Core i7. Tatsächlich unterscheiden sich die i3- und i7-Modelle vom Pentium und i5 nur in der Größe des Third-Level-Cache pro Kern (die Taktfrequenz natürlich nicht mitgerechnet). Das erste Paar hat 1,5 Megabyte und das zweite Paar hat 2 Megabyte. Dieser Unterschied kann die Leistung von Prozessoren nicht grundsätzlich beeinflussen, da der Unterschied in der Cache-Größe sehr gering ist. Aus diesem Grund erhielten Core i3 und Core i7 Unterstützung für die Hyper-Threading-Technologie, die das Hauptelement darstellt, das diesen Prozessoren einen Leistungsvorteil gegenüber Pentium bzw. Core i5 ermöglicht.
Dadurch ermöglichen ein etwas größerer Cache und Hyper-Threading-Unterstützung deutlich höhere Preise für Prozessoren. Beispielsweise sind Prozessoren der Pentium-Reihe (ca. 10.000 Tenge) etwa doppelt so günstig wie Core i3 (ca. 20.000 Tenge), und dies trotz der Tatsache, dass sie physisch und auf Hardwareebene absolut identisch sind und dementsprechend , haben die gleichen Kosten . Der Preisunterschied zwischen Core i5 (ca. 30.000 Tenge) und Core i7 (ca. 50.000 Tenge) ist ebenfalls sehr groß, bei jüngeren Modellen jedoch weniger als doppelt so hoch.

Wie gerechtfertigt ist diese Preiserhöhung? Welchen echten Gewinn bietet Hyper-Threading? Die Antwort ist seit langem bekannt: Die Steigerung variiert, alles hängt von der Anwendung und ihrer Optimierung ab. Wir haben uns entschlossen zu prüfen, was HT in Spielen als einer der anspruchsvollsten „Haushalts“-Anwendungen leisten kann. Darüber hinaus ist dieser Test eine hervorragende Ergänzung zu unserem vorherigen Material zum Einfluss der Anzahl der Kerne im Prozessor auf die Spieleleistung.
Bevor wir mit den Tests fortfahren, sollten wir uns daran erinnern (oder herausfinden), was Hyper-Threading-Technologie ist. Wie Intel selbst bei der Einführung dieser Technologie vor vielen Jahren sagte, ist sie nicht besonders kompliziert. Tatsächlich ist zur Einführung von HT auf der physischen Ebene lediglich erforderlich, nicht einen Satz Register und einen Interrupt-Controller zu einem physischen Kern hinzuzufügen, sondern zwei. IN Pentium-Prozessoren 4 Diese zusätzlichen Elemente erhöhten die Anzahl der Transistoren nur um fünf Prozent. In modernen Ivy-Bridge-Kernen (sowie Sandy Bridge und zukünftigem Haswell) erhöhen die zusätzlichen Elemente für selbst vier Kerne den Chip nicht einmal um 1 Prozent.

Zusätzliche Register und ein Interrupt-Controller gepaart mit Softwareunterstützung ermöglichen es dem Betriebssystem, nicht einen physischen Kern, sondern zwei logische zu sehen. Gleichzeitig erfolgt die Verarbeitung der vom System gesendeten Daten aus zwei Streams immer noch auf demselben Kern, jedoch mit einigen Funktionen. Einem Thread steht weiterhin der gesamte Prozessor zur Verfügung, sobald jedoch einige CPU-Blöcke frei werden und sich im Leerlauf befinden, werden diese sofort an den zweiten Thread übergeben. Dadurch war es möglich, alle Prozessorblöcke gleichzeitig zu nutzen und dadurch die Effizienz zu steigern. Wie Intel selbst angibt, kann die Leistungssteigerung unter idealen Bedingungen bis zu 30 Prozent betragen. Allerdings gelten diese Indikatoren nur für den Pentium 4 mit seiner sehr langen Pipeline; moderne Prozessoren profitieren weniger von HT.
Doch nicht immer sind ideale Bedingungen für Hyper-Threading gegeben. Und was am wichtigsten ist: Das schlechteste Ergebnis von HT ist nicht der fehlende Leistungszuwachs, sondern dessen Rückgang. Das heißt, unter bestimmten Bedingungen sinkt die Leistung eines Prozessors mit HT im Vergleich zu einem Prozessor ohne HT, da der Overhead der Thread-Aufteilung und Warteschlange den Gewinn aus der Verarbeitung paralleler Threads, der in diesem Fall möglich ist, deutlich übersteigt Fall. Und solche Fälle kommen viel häufiger vor, als Intel lieb ist. Darüber hinaus hat der langjährige Einsatz von Hyper-Threading die Situation nicht verbessert. Dies gilt insbesondere für Spiele, die sehr komplex sind und hinsichtlich der Datenberechnung und Anwendungen überhaupt nicht dem Standard entsprechen.
Um herauszufinden, welche Auswirkungen Hyper-Threading auf die Spieleleistung hat, verwendeten wir erneut unseren leidgeprüften Testprozessor Core i7-2700K und simulierten vier Prozessoren gleichzeitig, indem wir Kerne deaktivierten und HT ein-/ausschalteten. Herkömmlicherweise können sie als Pentium (2 Kerne, HT deaktiviert), Core i3 (2 Kerne, HT aktiviert), Core i5 (4 Kerne, HT deaktiviert) und Core i7 (4 Kerne, HT aktiviert) bezeichnet werden. Warum bedingt? Erstens, weil sie aufgrund einiger Merkmale nicht den realen Produkten entsprechen. Insbesondere führt das Deaktivieren von Kernen nicht zu einer entsprechenden Verringerung des Volumens des Third-Level-Cache – sein Volumen beträgt für alle 8 Megabyte. Darüber hinaus arbeiten alle unsere „bedingten“ Prozessoren mit der gleichen Frequenz von 3,5 Gigahertz, was noch nicht von allen Prozessoren der Intel-Reihe erreicht wurde.

Dies ist jedoch sogar zum Besseren, da wir dank der ständigen Änderung aller wichtigen Parameter den tatsächlichen Einfluss von Hyper-Threading auf die Spieleleistung ohne Bedenken herausfinden können. Und der prozentuale Leistungsunterschied zwischen unserem „bedingten“ Pentium und Core i3 wird nahe dem Unterschied zwischen echten Prozessoren liegen, vorausgesetzt, die Frequenzen sind gleich. Es sollte auch nicht verwirren, dass wir einen Prozessor mit Sandy-Bridge-Architektur verwenden, da unsere Effizienztests, die Sie im Artikel „Bare Performance – Untersuchung der Effizienz von ALUs und FPUs“ nachlesen können, gezeigt haben, dass der Einfluss von Hyper- Das Threading in den neuesten Generationen von Prozessorkernen bleibt unverändert. Höchstwahrscheinlich relevant dieses Material wird auch für kommende Haswell-Prozessoren verfügbar sein.
Nun, es scheint, dass alle Fragen zur Testmethodik sowie zu den Betriebsfunktionen der Hyper-Threading-Technologie besprochen wurden, und daher ist es an der Zeit, zum Interessantesten überzugehen – den Tests.
Selbst in einem Test, in dem wir den Einfluss der Anzahl der Prozessorkerne auf die Spieleleistung untersuchten, stellten wir fest, dass der 3DMark 11 hinsichtlich der CPU-Leistung völlig entspannt ist und sogar auf einem Kern perfekt funktioniert. Hyper-Threading hatte den gleichen „mächtigen“ Einfluss. Wie Sie sehen, stellt der Test keine Unterschiede zwischen Pentium und Core i7 fest, von Zwischenmodellen ganz zu schweigen.

Metro 2033
Aber Metro 2033 hat das Aufkommen von Hyper-Threading deutlich bemerkt. Und sie reagierte negativ auf ihn! Ja, das stimmt: Die Aktivierung von HT in diesem Spiel wirkt sich negativ auf die Leistung aus. Ein kleiner Einfluss natürlich – 0,5 Bilder pro Sekunde bei vier physischen Kernen und 0,7 bei zwei. Aber diese Tatsache gibt allen Grund zu der Annahme, dass der Metro 2033 Pentium schneller ist als der Core i3 und der Core i5 besser als der Core i7. Dies ist eine Bestätigung dafür, dass Hyper-Threading seine Wirksamkeit nicht immer und nicht überall zeigt.

Crysis 2
Dieses Spiel zeigte sehr interessante Ergebnisse. Zunächst stellen wir fest, dass der Einfluss von Hyper-Threading bei Dual-Core-Prozessoren deutlich sichtbar ist – der Core i3 liegt fast 9 Prozent vor dem Pentium, was für dieses Spiel ziemlich viel ist. Sieg für HT und Intel? Eigentlich nicht, denn der Core i7 konnte im Vergleich zum deutlich günstigeren Core i5 keinen Zuwachs verzeichnen. Dafür gibt es aber eine vernünftige Erklärung: Crysis 2 kann nicht mehr als vier Datenströme nutzen. Aus diesem Grund sehen wir einen guten Anstieg beim Dual-Core mit HT – dennoch sind vier Threads, wenn auch logisch, besser als zwei. Auf der anderen Seite gab es keine Möglichkeit, zusätzliche Core-i7-Threads unterzubringen; vier physische Kerne reichten vollkommen aus. Basierend auf den Ergebnissen dieses Tests können wir also den positiven Einfluss von HT im Core i3 feststellen, der hier deutlich besser ist als der Pentium. Aber unter den Quad-Core-Prozessoren scheint der Core i5 wiederum eine vernünftigere Lösung zu sein.

Battlefield 3
Die Ergebnisse hier sind sehr seltsam. Wenn Battlefield im Test zur Anzahl der Kerne ein Beispiel für einen mikroskopischen, aber linearen Anstieg war, dann führte die Einbeziehung von Hyper-Threading zu Chaos in den Ergebnissen. Tatsächlich können wir sagen, dass der Core i3 mit seinen zwei Kernen und HT der Beste von allen war, sogar vor dem Core i5 und Core i7. Es ist natürlich seltsam, aber gleichzeitig lagen Core i5 und Core i7 wieder auf dem gleichen Niveau. Was dies erklärt, ist nicht klar. Höchstwahrscheinlich spielte hier die Testmethodik in diesem Spiel eine Rolle, die größere Fehler liefert als Standard-Benchmarks.

Im letzten Test erwies sich F1 2011 als eines der Spiele, bei denen die Anzahl der Kerne sehr kritisch ist, und überraschte uns auch in diesem Test erneut mit dem hervorragenden Einfluss der Hyper-Threading-Technologie auf die Leistung. Und auch hier funktionierte die Einbindung von HT, wie schon in Crysis 2, auf Dual-Core-Prozessoren sehr gut. Schauen Sie sich den Unterschied zwischen unserem herkömmlichen Core i3 und unserem Pentium an – er ist mehr als doppelt so groß! Es ist deutlich zu erkennen, dass dem Spiel deutlich zwei Kerne fehlen, und gleichzeitig ist sein Code so gut parallelisiert, dass der Effekt verblüffend ist. Mit vier physischen Kernen kann man dagegen nicht streiten – der Core i5 ist spürbar schneller als der Core i3. Aber auch hier zeigte der Core i7, wie schon in den vorherigen Spielen, nichts Herausragendes im Vergleich zum Core i5. Der Grund ist derselbe: Das Spiel kann nicht mehr als 4 Threads verwenden und der Overhead beim Ausführen von HT reduziert die Leistung des Core i7 unter das Niveau des Core i5.

Ein alter Krieger braucht Hyper-Threading genauso wenig wie ein Igel ein T-Shirt – sein Einfluss ist bei weitem nicht so deutlich spürbar wie in F1 2011 oder Crysis 2. Wir stellen jedoch immer noch fest, dass das Einschalten von HT auf einem Dual-Core-Prozessor brachte 1 zusätzlichen Rahmen. Dies reicht sicherlich nicht aus, um zu sagen, dass Core i3 besser als Pentium ist. Zumindest entspricht diese Verbesserung eindeutig nicht dem Preisunterschied dieser Prozessoren. Und der Preisunterschied zwischen Core i5 und Core i7 ist nicht einmal erwähnenswert, da sich der Prozessor ohne HT-Unterstützung erneut als schneller herausstellte. Und spürbar schneller – um 7 Prozent. Was auch immer man sagen mag, wir weisen erneut darauf hin, dass vier Threads das Maximum für dieses Spiel sind und HyperThreading in diesem Fall dem Core i7 nicht hilft, sondern behindert.







