Ocr շրջանակը և օգտագործումը: Որոնք են ocr համակարգերը: Տեքստային սիմվոլների պատկերների նախնական մշակման և հատվածավորման մեթոդներ
Ինչպես բազմիցս ապացուցվել է, ծուլությունը առաջընթացի շարժիչ ուժն է: Մարդը շատ ծույլ էր քայլելու համար - հայտնվեց մեքենա, շատ ծույլ էր գնալ քաղաքի մյուս ծայրը ընկերոջ հետ խոսելու համար - հայտնվեց հեռախոս, չափազանց ծույլ էր հագնվել և գնալ թատրոն - ստեղծվեց հեռուստացույց և այլն: անվերջ: Ծուլությունը բերեց արտաքին տեսքին ծրագրային արտադրանքորը կքննարկվի այս հոդվածում:
Ինչու՞ մուտքագրել տեքստ, եթե ինչ-որ մեկը նախկինում դա արել է: Օգտագործողի համար նման առաջադրանքը բռնի դիմադրություն է առաջացնում՝ վրդովմունքի խառնուրդով՝ ուրիշի աշխատանքը կրկնօրինակելու համար: Համակարգչի օգնությունը, որն արդեն գիտեր հաշվել, նկարել և շատ այլ բաներ անել մարդու համար, անհրաժեշտ դարձավ մեկ այլ ոլորտում։ Բնականաբար, մշակողները ծրագրային ապահովումչէր կարող անտարբեր մնալ նման աղաղակող անարդարության հանդեպ, որի վերացումը, առավել եւս, խոստանում էր զգալի դիվիդենտներ։ Ահա թե ինչպես են ստեղծվել համակարգերը. արհեստական բանականություն, Ռուսաստանում հայտնի է որպես տեքստի ճանաչման օպտիկական համակարգեր, իսկ անգլիախոս երկրներում՝ որպես օպտիկական նիշերի ճանաչում (OCR):
Ընդհանուր առմամբ, ժամանակակից OCR ծրագրի աշխատանքը հետևյալն է. սկանավորված պատկերի վրա ընտրելով օբյեկտներ, որոնք կարող են տառեր լինել, համակարգը հաշվարկում է դրանցից յուրաքանչյուրի համար որոշակի պարամետրերի փաթեթ (օրինակ, օրինակ՝ սև կետերի խտությունը անկյունագծով): Այնուհետև ստացված արժեքները հերթով համեմատվում են ստանդարտների հետ՝ հայտնի նշանների համար հաշվարկված նույն պարամետրերի հավաքածուներով: Կախված այն ստանդարտից, որի համար պարամետրերի տարբերությունն ամենափոքրն է, համակարգը որոշում է, թե որ նշանը պետք է համարվի հայտնաբերված օբյեկտ:
Այսօր OCR ծրագրաշարի օգտագործման ոլորտը զգալիորեն ընդլայնվել է. սկզբում այն օգտագործվում էր ֆինանսական և բանկային ոլորտում, իսկ հետո ցանկացած փաստաթղթերի հետ աշխատելու համար: Դժվար է գերագնահատել OCR համակարգերի կարևորությունը, որոնք դարձել են կարևոր ծրագրակազմ ինչպես գրասենյակային, այնպես էլ տնային համակարգիչների համար: Հեղինակին, ինչպես, հավանաբար, շատ ընթերցողներ, իր աշխատանքային կյանքի ընթացքում ուղեկցում են տեքստի ճանաչման համակարգեր՝ սկսած (խոստովանում եմ!) ուրիշների ռեֆերատների սկանավորումից և իր սիրելի ամսագրի էլեկտրոնային արխիվ ստեղծելուց և վերջացրած փաստաթղթերի համակարգվածությամբ։ ոչ մի տեղից և լրացրեց գրասեղանի ամբողջ տարածքը: Հետևաբար, ընթացիկ հատուկ համարում, գրաֆիկական խմբագրիչների և հակավիրուսային նյութերի հետ մեկտեղ, OCR-ին նվիրված հոդվածի հայտնվելը տրամաբանական է դարձել:
Որտեղի՞ց է առաջացել OCR-ը
Ավտոմատ ճանաչման փորձերը ձեռնարկվել են XX դարի 30-ական թվականներից, սակայն առաջին OCR մեքենան. Ամերիկյան ընկերություն Intelligent Machines Research Corporation-ը հայտնվեց միայն 1952 թվականին: Բնականաբար, այդ ժամանակ որեւէ արհեստական ինտելեկտի մասին խոսք չկար։ Առաջին OCR մեքենաները նույնիսկ կապ չունեին համակարգչային տեխնիկա. Դրանցում բնօրինակի լուսավորված տարածքից արտացոլված լույսն անցնում էր հայելիների բարդ համակարգով, որոնցից մի քանիսը գտնվում էին պտտվող սկավառակների վրա: Արդյունքում, նեղ լույսի ճառագայթները հերթափոխով առանձնացվել են ընդհանուր հոսքից՝ համապատասխան բնօրինակի փոքր տարածքներին՝ էլեկտրոնային պատկերի պիքսելների անալոգներին: Այս «քվազի-պիքսելները» սնվում էին ֆոտոբազմապատկիչի՝ օպտիկա-էլեկտրոնային փոխարկիչի մուտքին՝ բարձր հզորությամբ: Ստացված ազդանշանները մշակվել են էլեկտրոնային միացում. Մշակման ընթացքում պարզվեց՝ բնօրինակի ընդգծված կետը սպիտակ է, թե սև։ Ստացված տեղեկատվության հիման վրա OCR մեքենան վերարտադրել է լուսավորված նշանի պատկերը։
Այս մեքենաների հնարավորությունները սահմանափակվում էին մի շարք պայմաններով։ Բացառիկ լավ որակ, բարձր հակադրություն և բնօրինակների որևէ վնասի բացակայություն պահանջվում էր ցանկացած տեսակի վստահ ճանաչման համար: Բացի այդ, ոչ բոլոր մակագրությունները կարող էին ճանաչել, այլ միայն որոշակի տառատեսակներով մուտքագրվածները: Հենց այդ նպատակով էլ 60-ականներին մշակվեցին և ստանդարտացվեցին հատուկ տառատեսակներ՝ OCR-A (ԱՄՆ-ում) և OCR-B (Եվրոպայում):
1970-ականներին Kurzweil Computer Products-ը OCR-ն տեղափոխեց հաջորդ մակարդակ՝ ստեղծելով համակարգ, որը կարող էր սովորել ճանաչել տառատեսակները: Դասընթացի արդյունքները, որոնք սովորաբար տեւում էին մի քանի ժամ, գրվում էին սկավառակի վրա, և համակարգը ձեռք էր բերում սովորած տառատեսակով մուտքագրված տեքստերը ճանաչելու հնարավորություն։ Միևնույն ժամանակ, Ալեքսանդր Շամիսի գլխավորած խումբը հետազոտություն է անցկացրել «ձեռքով տպագրված» (ձեռագիր տառերով գրված) մակագրությունների ճանաչման վերաբերյալ Էլեկտրոնային և համակարգչային տեխնիկայի ռուսական հետազոտական կենտրոնում (NICEVT CCSR): Հետագայում խմբի գործունեության արդյունքները բազմիցս մարմնավորվել են ծրագրի կոդը. Ամենահայտնի OCR համակարգը, որը գործնականում իրականացնում է Shamis խմբի մեթոդները, Ռուսաստանում ստեղծված ABBYY FineReader-ն է, որն ավելի մանրամասն կքննարկվի ստորև։
1986թ.-ին Calera Recognition Systems-ը մշակեց մի համակարգ, որը թույլ տվեց նրանց աշխատել անհայտ տառատեսակներով՝ առանց նախնական ուսուցման բազմաթիվ ժամերի: Սա առաջին OCR համակարգն էր, որն ունի արհեստական ինտելեկտ: Նախկինում օգտագործված նիշ առ նիշ օրինաչափության համընկնման տեխնիկայի փոխարեն, այն գործում էր ընդհանրացման մեթոդի համաձայն, որն այժմ ավելի հայտնի է որպես սկզբունք. նեյրոնային ցանց. Մշակողները ծրագրին տրամադրել են ավելի քան 10000 նախշեր յուրաքանչյուր տառի համար; ընդհանրացնելով դրանք՝ համակարգը պատկերացում ստացավ կերպարի մակագրության հիմնական օրինաչափությունների մասին, ինչը հնարավորություն տվեց անել առանց երկար ուսուցման։ Այնուամենայնիվ, որոշակի վերապատրաստում է պահանջվում նաև ժամանակակից OCR ծրագրերի համար: Օրինակ՝ երբեմն անհրաժեշտ է լինում «կրթական ծրագիր» իրականացնել հազվագյուտ և դեկորատիվ տառատեսակներ ճանաչելիս։
Անցյալ դարի վերջում OCR-ի նոր մոտեցումը գործնականում ներդրվեց՝ օգտագործելով մշուշոտ տրամաբանություն: Ծրագիրը առաջ քաշեց ոչ թե մեկ, այլ մի քանի վարկած յուրաքանչյուր խորհրդանիշի վերաբերյալ, և դրանցից յուրաքանչյուրին տրվեց վարկանիշ, որն արտացոլում է այս վարկածի նկատմամբ վստահության աստիճանը։ Վարկածների ցուցակները մշակելիս հաշվի են առնվել տարբեր հանգամանքներ, օրինակ՝ ստացված բառի առկայությունը կամ բացակայությունը բառարանում, մինչդեռ յուրաքանչյուր վարկածի վարկանիշը համապատասխանաբար փոխվել է։ Ի վերջո, ցուցակները հայտնվեցին այսպես կոչված փորձագետի տրամադրության տակ՝ ընտրության ալգորիթմը, որն ուներ վերջնական խոսքը։ Որպես կանոն, նման համակարգերում ճիշտ է համարվում այն խորհրդանիշը, որի վարկածը ստացել է առավելագույն ընդհանուր վարկանիշ։
Հարկ է նշել, որ ժամանակակից OCR համակարգերը լուծում են շատ ավելի բարդ խնդիրներ, քան իրենց նախորդները: Այժմ դուք ոչ մեկին չեք զարմացնի տեքստի պարզ ճանաչմամբ: Օգտատերերի կարիքներն աճել են, և փաստաթուղթը, որը պետք է ճանաչվի, հաճախ շատ ավելի բարդ է թվում, քան սև տեքստով սպիտակ էջը՝ նկարազարդումներ, աղյուսակներ, վերնագրեր, ստորագիր, ֆոնային պատկերներև դիզայնի այլ տարրերը բարդացնում են դրա կառուցվածքը: Ճիշտ վերարտադրելու համար էլեկտրոնային ձևաչափովՆման փաստաթղթերը, բոլոր ժամանակակից OCR ծրագրերը սկսում են ճանաչումը հենց կառուցվածքի վերլուծությունից: Որպես կանոն, առանձնանում են մի քանի հիերարխիկ կազմակերպված տրամաբանական մակարդակներ. Ամենաբարձր մակարդակի միայն մեկ օբյեկտ կա՝ հենց էջը, հիերարխիայի հաջորդ մակարդակում կա աղյուսակ և տեքստային բլոկ, այնուհետև աղյուսակի բջիջ, պարբերություն կամ նկար, որին հաջորդում է տող, այնուհետև բառ կամ նկարը տողի մեջ, և վերջապես, ստորին մակարդակը խորհրդանիշ է:
Հասկանալի է, որ ցանկացած բարձր մակարդակի օբյեկտ կարող է ներկայացվել որպես ավելի ցածր մակարդակի օբյեկտների հավաքածու՝ տառերը կազմում են բառեր, բառերը՝ տողեր և այլն։ Հետեւաբար, վերլուծությունը միշտ սկսվում է վերեւից ներքեւ: Ծրագիրը էջը բաժանում է օբյեկտների, որոնք էլ իրենց հերթին՝ օբյեկտների ավելի ցածր մակարդակներև այլն, մինչև կերպարներ: Երբ նիշերը ընտրվում և ճանաչվում են, սկսվում է հակառակ գործընթացը՝ ավելի բարձր մակարդակի օբյեկտների հավաքում, որն ավարտվում է մի ամբողջ էջի ձևավորմամբ։ Այս ընթացակարգը կոչվում է բազմամակարդակ փաստաթղթերի վերլուծություն կամ MDA (Multilevel document Analysis):
Այսպիսով, մեկ կերպար ճանաչելու խնդիրը, որի վրա շատ մասնագետներ աշխատել են վերջին կես դարում, թեև այն չունի. իդեալական լուծում, բայց դրան մոտ, և, հետևաբար, որոշ չափով նահանջեց երկրորդ պլան՝ դառնալով օգտատիրոջը թղթային էջից դեպի էլեկտրոնային պատճենը տանող տրամաբանական սանդուղքի բազմաթիվ քայլերից մեկը:
Համակարգչին կարդալ սովորեցնելը հեշտ գործ չէ, և չնայած այս ոլորտում զգալի առաջընթացին, սխալները ժամանակ առ ժամանակ սայթաքում են (սովորաբար առատ գրաֆիկական ընդգրկումներով փաստաթղթերում): Բայց քանի որ ճանաչումը սովորաբար շատ ավելի քիչ ժամանակ է պահանջում, քան ստեղնաշարից նույն քանակությամբ տեքստ մուտքագրելը, առաջընթացն ակնհայտ է: «Սովորաբար» բառերը պատահական չեն օգտագործվում։ Լինում են կլինիկական դեպքեր, երբ դուք պետք է տառապեք ամսագրի որոշ էջերից, որոնք պարունակում են բազմաթիվ նկարազարդումներ և աղյուսակներ, որոնք համառորեն հրաժարվում են ընդունել իրենց սկզբնական դիրքը վերջնական տարբերակում և բոլորը ձգտում են ինչ-որ տեղ սահել՝ իրենց հետ քաշելով տեքստը:
Համաձայն ABBYY-ի կողմից իր FineReader արտադրանքի օգտատերերի շրջանում անցկացված հարցումների արդյունքների, որոնք կքննարկվեն ստորև, օգտատերերը վերագրում են հետևյալը ճանաչման համակարգերի գործունեության ամենակարևոր ասպեկտներին.
- ճանաչման ճշգրտությունը 95%;
- տեքստի մշակման համար նախատեսված փաստաթղթերում դիզայնի պահպանման ճշգրտությունը (MS Word, MS Excel, Word Pro, Word Perfect ձևաչափերով) - 89%;
- դիզայնի պահպանման ճշգրտությունը հետագա էլեկտրոնային հրապարակման համար (in PDF ձևաչափեր, HTML) - 87%;
- աշխատանք աղյուսակների և բազմասյուն տեքստերի հետ՝ 87%;
- օգտագործման հեշտությունը 85%;
- աշխատանքի հուսալիությունը 82%;
- Սխալների հարմար որոնում և բնօրինակի հետ հաշտեցում - 80%;
- աշխատել գույնի հետ (գունային պատկերների, տառատեսակի և ֆոնի գույների պահպանում) - 63%;
- ուղղակի արտահանում դեպի այլ հավելվածներ՝ 61%;
- արագությունը 55%;
- բազմալեզու ճանաչում 25%:
Խնդրում ենք նկատի ունենալ, որ վեբ ձևաչափերի արտահանումը անհրաժեշտ տարբերակ է համարվել օգտատերերի 87%-ի կողմից: Այսպիսով, ինտերնետում ճանաչման արդյունքների տեղադրման հնարավորությունը դառնում է ավելի առաջնահերթ, քան OCR-ի և ընդհանրապես ծրագրային արտադրանքի համար այնպիսի կարևոր պահանջներ, ինչպիսիք են ինտերֆեյսի հարմարավետությունն ու պարզությունը և աշխատանքի հուսալիությունը: Թվում է, թե ցանցային գործոնը գնալով ավելի ակտուալ է դառնում նույնիսկ ինտերնետին ուղղակիորեն չմիացված տարածքներում։ Այս դեպքում OCR-ի կցումը համացանցին կարող է մեծապես բացատրել ինտերնետում հայտնվելով միանգամայն տարբեր թեմատիկ ուղղվածության բազմաթիվ գրադարանների, որոնք պարունակում են փաստաթղթերի և հրապարակումների էլեկտրոնային պատճեններ: Նման վիրտուալ ընթերցասրահների թիվն օրեցօր ավելանում է, ինչպես նաև դրանց ժողովրդականությունը։ Վերջերս, սակայն, նրանց գլխին ամպեր սկսեցին կուտակվել՝ հասնելով հեղինակային իրավունքի չեմպիոններին, բայց դա այլ պատմություն է։
Ներկայումս ճանաչման համակարգերի շուկայում կան մի շարք զարգացումներ, որոնք ուղղված են ինչպես օգտատերերի գործունեության տարբեր ոլորտներին, այնպես էլ տարբեր հարթակներում: Շուկայի առանձին ճյուղը կենտրոնացած է Mac հարթակի վրա։ Գրեթե բոլոր հայտնի ճանաչման համակարգերը ներկայումս ունեն տարբերակներ «խնձորի» մտքի համար: ABBYY FineReader-ը շարունակում է մնալ Ռուսաստանում OCR համակարգերի վաճառքի բացարձակ առաջատարը և մի քանի տարի արտերկրում վաճառքի առաջատարներից մեկը:
«Գեղեցիկ ընթերցող» և նրա նմանները
MIPT չորրորդ կուրսի ուսանող Դեյվիդ Յանի մտահղացումը, BIT Software-ը ծնվել է 1989 թվականին: 1997 թվականին այն ստացավ իր ժամանակակից անվանումը՝ ABBYY Software House, իսկ մեկ տարի անց այն մտավ համաշխարհային շուկա իր հիմնական FineReader արտադրանքով։ Այն ժամանակ նման քայլը արկածախնդիր էր թվում, քանի որ OCR հսկաները, ինչպիսիք են Caere-ը OmniPage ճանաչման համակարգով և ScanSoft-ը TextBridge-ով, իշխում էին Արևմուտքում, և շուկան հագեցած և բաժանված էր: Սակայն սկիզբը շատ հաջող ստացվեց ABBYY-ի համար։ Վերջին մի քանի տարիների ընթացքում ABBYY-ին հաջողվել է հետ նվաճել OCR համակարգերի համաշխարհային շուկայի մոտ 20%-ը իր մրցակիցներից, և ամեն տարի ավելի ու ավելի շատ օգտվողներ անցնում են այլ մշակողների ծրագրերից FineReader՝ գնահատելով այս համակարգի առավելությունները: ABBYY-ն պայմանագրեր է կնքել սկաներների այնպիսի խոշոր արտադրողների հետ, ինչպիսիք են Mustek-ը, Acer-ը, Compaq-ը, Lexmark-ը՝ FineReader-ին ամբողջությամբ մատակարարելու իրենց սկաներներն ու MFP-ները: ABBYY-ի դիլերներն ու գործընկերները գործում են աշխարհի 80 երկրներում, իսկ ընկերությունն ինքը գրասենյակներ ունի ԱՄՆ-ում, Գերմանիայում, Մեծ Բրիտանիայում, Շվեդիայում և Ուկրաինայում: FineReader-ին հաջողվել է փոխել յոթ տարբերակ, ստացել է ավելի քան հարյուր մրցանակ տարբեր միջազգային հրատարակությունների և թեստային լաբորատորիաների թեստերում, և մինչ օրս, չնայած ABBYY-ի մի շարք այլ ծրագրային լուծումների, այն մնում է ընկերության առաջատար արտադրանքը՝ ապրելով բացարձակ: համակարգիչների մեծամասնությունը, համենայն դեպս՝ ռուսական:
Ներկայումս FineReader-ի երկու վերջին տարբերակները համապատասխան են՝ 6.0 և 7.0, որոնք թողարկվել են համապատասխանաբար 2002 և 2003 թվականներին: Վեցերորդ տարբերակը հեղափոխեց OCR շուկան իր ժամանակին: Արտադրանքն օգտագործեց նոր ալգորիթմներ հարմարվողական երկուականացման և հյուսվածքների զտման համար, այլ կերպ ասած, դիզայնի նրբություններով փաստաթղթերի ճանաչման ճշգրտությունը, ինչպիսիք են գունավոր ֆոնի վրա տեքստը, գունավոր տառատեսակները, բազմասյուն տեքստը, կտրուկ աճել է: Այս շքեղության անձեռնմխելի պահպանումը, ներառյալ HTML-ում, նույնպես զգալիորեն բարելավվել է: Միևնույն ժամանակ, դիզայնի տարրերի ճանաչման որակն այժմ կարելի է գնահատել առանց արդյունքը արտահանելու բառամշակիչկամ բրաուզերում, բայց իր սեփական բազմասյունակ WYSIWYG խմբագրիչով: PDF-ն ավելացվել է ճանաչման համար հարմար «հում» ձևաչափերին։ Բացի խմբագրումից այս ձևաչափըհնարավոր է դարձել պահպանել աշխատանքի արդյունքները։ PDF-ի հետ աշխատելու ունակությունը դարձել է FineReader-ի վեցերորդ տարբերակի, թերեւս, ամենաօգտակար նորարարությունը:
Յոթերորդ տարբերակը այս պահին- արարչության պսակը, ձեռք է բերել մի շարք նոր օգտակար գործառույթներ։ Բարելավվել են արդեն նշված երկուականացման և զտման ալգորիթմները և մշակվել է նոր կառուցվածքային դասակարգիչ։ Ըստ ABBYY-ի՝ սա 25%-ով ավելացրել է ճանաչման ճշգրտությունը, բարդ դասավորությունները սկսել են ավելի լավ ճանաչել 33%-ով, իսկ անգլերենի և գերմաներենի իրավական և բժշկական բառարանների ավելացմամբ՝ մասնագիտացված տեքստերի ճանաչումը 30-ով դարձել է ավելի անսխալ։ -40%. Մենք չմոռացանք նախորդ տարբերակի «ձիու» մասին՝ PDF: PDF փաստաթղթերի ճանաչման ճշգրտությունն աճել է 45%-ով, իսկ FineReader գրիչի PDF ֆայլերը օպտիմիզացվել են առցանց հրապարակման համար 1: Բայց ներքին կորպորատիվ թեստերի արդյունքները, հատկապես քանակական, բավականին կոնկրետ են, և շատ խնդրահարույց է ինքներդ գնահատել նշված տոկոսների վավերականությունը։ Այսպիսով, գաղափարը, թե որքան ավելի արագ սկսեց գործել FineReader-ի վերջին «մարմնավորումը», ընթերցողները կարող են ինքնուրույն լրացնել: XML ձևաչափի աջակցությամբ FineReader-ն այժմ ինտեգրված է Microsoft Office Word 2003. Ինտեգրումն արտահայտվում է OCR-ի արդյունքների խմբագրման մեջ՝ օգտագործելով Word գործիքները բնօրինակի ընդլայնված աշխատանքային տարածքը դիտելիս: Դարձավ հնարավոր աշխատանքմեկ այլ Office հավելվածով՝ PowerPoint-ով: Պատկերների բաժանման գործիքների շնորհիվ FineReader-ը հեշտությամբ ճանաչում է շնորհանդեսների տպագրությունները, որոնք այնուհետև կարող են հեշտությամբ պահպանվել նաև PowerPoint ձևաչափով:
FineReader-ին չի շրջանցել նաև ծրագրակազմը մի քանի տարբերակների բաժանելու ավանդույթը, որոնք տարբերվում են ֆունկցիոնալությամբ և գնով, որը, ըստ երևույթին, հայտնվել է Microsoft-ի առաջարկով։ Ապրանքը գալիս է երկու ձևով՝ պրոֆեսիոնալ և կորպորատիվ հրատարակություն: Professional-ի յոթերորդ տարբերակը տեղափոխեց որոշ գործառույթներ, որոնք նախկինում հասանելի էին միայն կորպորատիվ տարբերակում: FineReader Professional օգտվողներն այժմ կարող են օգտագործել պատկերների բաժանման գործիքներ, ամբողջական տեքստի մորֆոլոգիական որոնում և շտրիխ կոդերի ճանաչում: Կորպորատիվ հրատարակությունը գործիքներ է ավելացնում ջենթլմենների OCR գործիքակազմում համատեղ աշխատանքմեջ տեղական ցանցԱվտոմատ ցանցի տեղադրում, օժանդակ ցանց բազմաֆունկցիոնալ սարքեր(օրինակ՝ սկաներ + պատճենահանող սարք + տպիչ) և կառավարման գործիքներ։
FineReader-ը գալիս է ևս երկու տարբերակով՝ Pro Mac-ի համար (ներկայումս վերջին տարբերակը 5.0 է) և Sprint: Առաջինը, ինչպես ենթադրում է անունը, նախատեսված է Apple-ի համակարգիչների վրա օգտագործելու համար: Հնարավորությունների և գնի առումով Mac-ի տարբերակը նման է պրոֆեսիոնալին և տարբերվում է ավելի փոքր թվով լեզուներով, որոնք աջակցվում են ճանաչման համար (117 ընդդեմ 177-ի), աջակցում է «խնձորի» տեխնոլոգիաներին (Quick Time, Drag-n): -Drop, Speech, Navigation Services) և AppleScript ինտերֆեյսը:
FineReader Sprint-ը արտադրանքի թեթև տարբերակն է, որը գալիս է սկաներներով և բազմաֆունկցիոնալ սարքերով, դա բավարար է սովորական աշխատանքի համար: Եթե, այնուամենայնիվ, անհրաժեշտություն կա լրացուցիչ հնարավորություններ, Sprint-ն ապահովում է լիարժեք տարբերակի թարմացման հնարավորություն:
Գինը. Corporate Edition-ը, ինչպես կարող եք ակնկալել, ամենաթանկն է՝ $259, Professional-ը և Pro-ն Mac-ի համար կես գնով են՝ $129:
Բացի FineReader-ից, ABBYY-ն շուկայում ներկայացնում է մի շարք ճանաչման ապրանքներ՝ ձեռքով լրացված մեծ թվով ձևաթղթերի ավտոմատ մշակման ծրագիր (ICR տեխնոլոգիա), ABBYY FormReader (ձևերը նշանակում են բոլոր տեսակի հարցաթերթիկներ, հարցաթերթիկներ, հաճախորդների դիմումներ, հարկային հայտարարագրեր և այլն) դ.); արտադրանք FineReader Bank վճարային փաստաթղթերի արագ մուտքագրման համար; TestReader գործիք՝ ուսումնական հաստատությունների քննական թեստերի, հարցաթերթիկների և այլ փաստաթղթերի արդյունքների մշակման համար։ Բացի ճանաչումից, ABBYY-ը մշակում է Lingvo էլեկտրոնային բառարաններ (վերջին տարբերակը՝ 9.0), ինչպես նաև լուծումներ է ստեղծում մշակողների և մշակողների համար։ համակարգի ինտեգրատորներ. Վերջիններս թույլ են տալիս ներդնել ճանաչման տեխնոլոգիաները (FineReader SDK), ամբողջական տեքստի որոնումը և լեզվաբանական վերլուծությունը (Retrieval & Morphology Engine) և ձևերի մշակումը (FormReader Developer Edition և FlexiCapture Studio) այլ ծրագրային արտադրանքներում:
Ավարտելով FineReader-ի մասին պատմվածքը՝ հարկ է նշել ABBYY-ի ևս մեկ ձեռքբերում՝ որպես այդպիսին ճանաչելուց հեռու: Ընկերության արտադրանքն ունի պաշտպանության ամենաբարձր մակարդակներից մեկը Ռուսաստանում: Նրանք օգտագործում են համակցված պաշտպանության մեթոդ, որը ներառում է գրանցում և դժվար պատճենվող կրիչներ: Որոշ դեպքերում (թանկ ապրանքների համար) ապրանքի հետ տրվում է էլեկտրոնային բանալի: Միայն յոթերորդ տարբերակից սկսած՝ FineReader-ը սկսեց մատակարարվել առանց ակտիվացման սկավառակի։ Այժմ այն կարելի է ակտիվացնել առցանց՝ հեռախոսով, ֆաքսով կամ էլ. Միևնույն ժամանակ, ABBYY-ի արտադրանքն ունի բազմաստիճան պաշտպանություն: Իհարկե, ծրագրերը դեռևս կոտրվում են, բայց բավականին հաճախ ոչ ամբողջությամբ, այլ միայն առաջին մի քանի մակարդակները, որոնց արդյունքում անօրինական պատճենը ճիշտ չի աշխատում կամ ամբողջությամբ դադարում է գոյություն ունենալ որոշակի ժամանակահատվածից հետո: Սա հասնում է ընկերության հիմնական նպատակին` առաջացնել օգտատերերի անվստահություն ծովահեն ծրագրային ապահովման համար: Բնականաբար, ABBYY-ն ստիպված էր այդքան ժամանակ և ջանք ծախսել ծովահենության դեմ զարգացումների վրա, ոչ թե լավ կյանքից: Ընկերությունը շոշափելի վնասներ է կրել 1989 թվականից, երբ իր էլեկտրոնային բառարան Lingvo-ն տարածվել է ամբողջ Ռուսաստանում՝ տասնյակ հազարավոր կեղծ օրինակներով։
Գործնական հիմունքներ
Սովորաբար, FineReader-ը վերանայելիս լրագրողները արտադրանքի տարբեր փորձարկումներ են անցկացնում «մարտական պայմաններում»՝ օգտագործելով ամսագրի շքեղ էջեր, հնագույն տողեր կամ հազվագյուտ լեզուներով տեքստեր: Այս անգամ ես կցանկանայի փոխել ավանդույթները պարզապես այն պատճառով, որ նման փորձերի արդյունքների հրապարակումը հեղինակին թվում է անօգուտ ընթերցողների համար։ Իրոք, օգտատերերի մեծամասնությունը հավանաբար կօգտագործի FineReader-ը՝ սովորականը ճանաչելու համար գրասենյակային փաստաթղթերկամ ամսագրերի հոդվածներ: Ճանաչման ճշգրտությունն այս դեպքում կլինի լավագույնը, և ավելի բարդ տարբերակների ամբողջ շարքը, որոնք խնդիրներ են առաջացնում, չեն կարող դիտարկվել, նույնիսկ եթե դրանց նվիրված է ամսագրի համարը: Ուստի որոշվեց ներկայացնել ընդհանուր կանոններաշխատել արտադրանքի հետ, որը յուրաքանչյուր ընթերցող կարող էր գործնականում կիրառել՝ անկախ իր առջեւ դրված խնդիրների առանձնահատկություններից։
Ծրագրի առաջին մեկնարկի ժամանակ, ինչպես նաև բոլոր հաջորդներում, եթե այս տարբերակն անջատված չէ, օգտագործողին ներկայացվում է ողջույնի պատուհան, որն առաջարկում է ընտրել հետևյալ աշխատանքային տարբերակները. փաստաթուղթ մուտքագրել՝ օգտագործելով Scan & Read wizard, սովորելով. օրինակներ և բացելով ցուցադրական օրինակ: Եթե ընտրեք վերջին տարբերակը, ծրագիրը կներբեռնի էջի TIFF պատկերը՝ գալակտիկաների տեղական խմբի մասին տեքստով՝ համեմված մի քանի նկարազարդումներով և աղյուսակով: Դե, օգտատերը պետք է մտածի, թե ինչպես մտքին բերի խնդիրը, այսինքն՝ նկարը տեքստի մեջ։ Դա մի փոքր նման է լող սովորեցնելու ամենաարդյունավետ միջոցին, երբ մարզիչը հիվանդասենյակը շպրտում է կողքից: Այնուամենայնիվ, այստեղ ամեն ինչ շատ ավելի պարզ է. Ինչպես և սպասվում էր, օգտատերը պետք է միայն պարզի, թե որ կոճակները պետք է սեղմել, ինչը դժվար չէ, քանի որ ինտերֆեյսը բավականին պարզ է, իսկ թեստային էջն ինքնին ճանաչվում է առանց անսարքության, առանց խայթոցի (նկ. 1):

Եթե ընտրեք «Սովորել օրինակով», ապա սովորական օգնության բաժինը կբացվի երեք հիմնական գլուխներով. Արագ ներածություն», «Օրինակներ» և «Խորհուրդներ»: Առաջինում օգտատիրոջը խորհուրդ է տրվում սկսել աշխատել՝ սեղմելով Scan & Read կոճակը, երկրորդում կա ճանաչված փաստաթղթերի առավել հաճախ օգտագործվող տեսակների ցանկը, երրորդի նպատակը, կարծում եմ, պարզ է. առանց բառերի.
Մշակողները FineReader-ի հետ աշխատելու բոլոր տարբերակները բաժանում են հետևյալ տասնվեց կատեգորիաների՝ պարզ նամակ, փաստաթուղթ՝ տեքստ մեկ սյունակում, բազմալեզու փաստաթուղթ, գրքի տարածում, ֆաքս, ամսագրի բարդ էջ, թերթի էջ, PDF փաստաթուղթ, պարզ աղյուսակ, սև բաժանարարների թերի քանակով աղյուսակ, բարդ աղյուսակ, այցեքարտ, Powerpoint-ի շնորհանդես, ծրագրային ապահովման տպում, դեկորատիվ տառատեսակ փաստաթուղթ, հոդվածի համարի փաստաթուղթ: Որոշ տարբերակների նկարագրությունը ուղեկցվում է իրավիճակի հայտարարությամբ և քայլ առ քայլ հրահանգներկոնկրետ խնդիրներ լուծելու համար։ Շատ հաճախ խորհուրդ է տրվում սկանավորել փաստաթուղթը GrayScale ռեժիմում, որն ավտոմատ կերպով սահմանում է օպտիմալ հակադրություն: Դեկորատիվ տառատեսակներ, ինչպես արդեն նշվեց, ծրագիրը պետք է ուսուցանվի։
Այս հոդվածի հաջորդ մի քանի պարբերությունները նախատեսված են սկսնակների համար, ուստի փորձառու օգտվողները կարող են բաց թողնել դրանք:
Այսպիսով, եկեք անմիջապես անցնենք աշխատանքի: Տեքստի ճանաչումը կարող է իրականացվել Scan&Read մոգով կամ առանց դրա: Գործիքագոտու ներքևի մասում կան հինգ մեծ կոճակներ՝ Scan&Read և կոճակներ, որոնք գործարկում են չորս հիմնական գործողությունները՝ Scan, Recognize, Verify և Save: Իմաստ ունի դիտարկել կախարդի հետ աշխատելու տարբերակը (նկ. 2):







Եթե Scan&Read-ը գործարկվում է, ապա առաջին հերթին օգտվողին հարցնում են՝ արդյոք նա ցանկանում է սկանավորել փաստաթուղթը, թե բեռնել այն ֆայլից: Առաջին դեպքում ցուցադրվում են սկաների ընթացիկ կարգավորումները՝ լուծաչափը, պայծառությունը և պատկերի տեսակը, և սկաների կառավարման ծրագիրը բեռնված է, իսկ երկրորդում հայտնվում է երկխոսության տուփ, որտեղ դուք պետք է ընտրեք «հումքը» ճանաչման համար: ձևաչափերից մեկը՝ BMP, DCX, JPEG, JPEG-2000, PCX, PNG, TIFF կամ PDF: Փաստաթուղթը սկանավորելուց/ավելացնելուց հետո ծրագրին հետաքրքրում է, թե ինչ լեզվով (լեզուներով) է գրված ճանաչման համար նախատեսված տեքստը: Ինչպես արդեն նշվեց, FineReader-ն աջակցում է 177 լեզուների, սակայն գործնականում հեղինակը դեռ ստիպված չի եղել փոխել լռելյայն «ռուսերեն-անգլերենը»: Ընտրելով և սեղմելով «Հաջորդը», կարող եք ուտել սենդվիչ, գնալ ծխելու, սուրճ խմել կամ ճաշել (կախված համակարգչի արագությունից և փաստաթղթի չափից), քանի որ ամենաերկար 2 գործընթացը սկսվում է իրականից: ճանաչում. Օգտագործողը կարող է դիտել դրա առաջընթացը, երբ ճանաչված հատվածները ընդգծված են կապույտով: Ավարտելուց հետո առաջարկվում է գնահատել արդյունքը՝ հայտնվում է երեք պատուհան, որոնցից մեկում ցուցադրվում է բնօրինակ պատկերը, երկրորդում՝ ստացված տեքստը, իսկ երրորդում՝ դրա մեծացված հատվածը։ «Պատկեր» պատուհանում կարող եք տեսնել, թե ինչպես է FineReader-ը բաժանել փաստաթղթի տեքստային, գրաֆիկական և աղյուսակային բաղադրիչները համարակալված բլոկների: Որպես տեքստ սահմանված բլոկները ուրվագծված են կանաչ, գրաֆիկական՝ կարմիր, աղյուսակային՝ կապույտ 3: Շտրիխ կոդերը լռելյայն չեն ճանաչվում, դրանք առանձին բլոկներում ընտրելու համար անհրաժեշտ է ենթամենյուի համապատասխան վանդակը: Ծառայություն -> Ընտրանքներ. Բլոկները խմբագրվում են պատուհանի ձախ կողմում գտնվող գործիքագոտու միջոցով: Յուրաքանչյուր գործիքի նպատակը հաղորդվում է, երբ կուրսորը տեղափոխում եք դրա վրայով, ուստի կարիք չկա մանրամասնորեն անդրադառնալ դրան: Խմբագրման բլոկների օրինակը ներկայացված է նկ. 3.

Բրինձ. 3. Լուսանկարի հետին պլանի տեքստը չի ճանաչվել և առանձնապես աչքի չի ընկել առանձին բլոկում։
Դա շտկելու համար պարզապես մկնիկի օգնությամբ ընտրեք համապատասխան տարածքը և համատեքստի ընտրացանկում ընտրեք «Ճանաչել»:
2 Իհարկե, պայմանով, որ արդյունքը քիչ թե շատ պարկեշտ լինի։ Հակառակ դեպքում, հետագա մշակումը կարող է տևել անորոշ ժամկետ:
3 Բոլոր գույները, իհարկե, կարող են փոխվել ըստ ձեր ցանկության՝ գործարկելով հրամանը. Ծառայություն -> Ընտրանքներ -> Դիտել.
Scan&Read վարպետը դիվանագիտորեն հարցնում է. «Ինչպե՞ս էր ճանաչումը»: Պետք է գնահատել դրական պատասխանի նրբանկատությունը՝ «Ընդհանուր առմամբ, հաջողությամբ»։ Արդյո՞ք մշակողները հույս չունեին լիովին հաջող ճանաչման վրա: Բացասական պատասխանի տարբերակն է՝ «Շատ վատ. սխալներ յուրաքանչյուր տողում»: Սա ձեզ համար ստանդարտ «լավ / վատ» չէ. անմիջապես զգացվում է օգտագործողի հոգեբանության խորը ըմբռնումը: (Կատակ:) Վերադառնալ աշխատանքի:
Եթե հանկարծ ճանաչման որակը բավարար չէ, օգտվողը հաջորդաբար ցուցադրվում է հնարավոր պատճառներըձախողումներ և համապատասխան խորհուրդներ. փոխեք սկանավորման կարգավորումները կամ օգտագործեք FineReader-ի հատուկ գործառույթները դժվար դեպքերի համար: Եթե որակը բավարար է, ապա ծրագիրն առաջարկում է ստուգել տեքստը ցանկացած հավելված արտահանելուց առաջ (նկ. 4):

Բրինձ. 4. Ներկառուցված ուղղագրիչը շատ նման է Word-ի ...
Ներկառուցված ուղղագրիչը շատ նման է Word-ին, միայն այն տարբերությամբ, որ պատուհանն ունի լրացուցիչ տարածք, որտեղ ցուցադրվում է բնօրինակ պատկերի համապատասխան ընդլայնված հատվածը, որտեղ տեղի է ունենում այս ստուգումը: Գործընթացի ավարտից հետո դուք պետք է ընտրեք աշխատանքի արդյունքների արտահանման վայր: Ի լրումն ֆայլի ստանդարտ պահպանման, դուք կարող եք անմիջապես փոխանցել ճանաչված փաստաթուղթը՝ հետագայում դիտելու և խմբագրելու համար Word, Excel, PowerPoint-ում, ինչպես նաև ուղարկել այն փոստով, պատճենել այն clipboard կամ ցուցադրել զննարկչի միջոցով: Դա ամբողջ աշխատանքային ցիկլն է: Այնուհետև կարող եք փակել հրաշագործը կամ սկսել աշխատել հաջորդ փաստաթղթի վրա:
Այլընտրանքային OCR-ներ
Շատ օգտատերերի տպավորություն է ստեղծվել, որ ABBYY FineReader-ը եզակի արտադրանք է: Ամենաառաջադեմները գիտեն, որ լատինատառ այբուբենը ճանաչելու առումով այն որոշակի մրցակցություն ունի, իսկ ինչ վերաբերում է կիրիլիցային այբուբենին, ապա այն հավանաբար այլևս գոյություն չունի։ Չորս տարի առաջ ABBYY-ի հիմնական մրցակիցը ներքին շուկայում Cognitive Technologies-ն էր՝ իր CuneiForm ճանաչման համակարգով: Բայց OCR for Cognitive-ն այլևս առաջնահերթություն չի համարվում. ընկերությունը հիմնականում զբաղվում է նախագծերի ինտեգրմամբ էլեկտրոնային առևտրի, փաստաթղթերի կառավարման և տեղեկատվական և վերլուծական համակարգերի ոլորտներում: Ճանաչողական ծրագրային ապահովման ամենահայտնի արտադրանքներից մեկը Եփրատ էլեկտրոնային փաստաթղթերի կառավարման համակարգն է: CuneiForm-ը, որը մի անգամ շնչում էր FineReader-ի գլխի հետևում, ի տարբերություն վերջինիս, դադարեց զարգանալ 2000-րդ տարբերակում (Professional and Master): Այնուամենայնիվ, CuneiForm-ը ներառված է նաև Ռուսաստանում վաճառվող որոշ սկաներների և բազմաֆունկցիոնալ սարքերի մեջ Canon, Hewlett-Packard, OKI, Seiko EPSON, Olivetti ընկերություններից: Չնայած այս «պապը» թույլ է տալիս արդյունքներ արտահանել պահպանված ձևաչափով, այն չի սովորել ճանաչել PDF-ը, այն աջակցում է ընդամենը 15 լեզուների, բայց միևնույն ժամանակ սխալ է ճանաչում փաստաթղթերը, որոնց տեքստը պարունակում է մեկից ավելի լեզու, բացառելով ստանդարտ ռուսերենը: Անգլերեն զույգ, ավտոմատ կերպով չի կողմնորոշվում տեքստային տողերը և այլն: Իհարկե, համապատասխան գնով կարելի է աչք փակել այս թերությունների վրա։ Բայց CuneiForm-ի դեպքում դա հնարավոր չէ անել, քանի որ Professional տարբերակն արժե $129, իսկ Master տարբերակն արժե $249, ինչը գրեթե նույնն է, ինչ FineReader-ը։ Պրոֆեսիոնալ տարբերակը, ի տարբերություն «արտադրամասի», չի կարող կատարել խմբաքանակային սկանավորում և ճանաչում և չունի «Եփրատ» անձնական էլեկտրոնային արխիվ։ Ըստ երևույթին, այս ծրագիրը կարող է առաջարկվել միայն նրանց, ովքեր օգտվում են Եփրատ համակարգից, քանի որ CuneiForm-ն աջակցում է այս արտադրանքի հետ ինտեգրմանը:
OCR-ի այլ զարգացումները ներառում են արտասահմանյան արտադրանք Readiris 9.0 I.R.I.S-ից: և OmniPage Pro 14.0-ը ScanSoft-ից: Readiris-ն առանձնանում է հիմնականում իր համեստ չափերով, ինչը չի խանգարում նրան ճանաչել LZW սեղմված TIFF պատկերներից տեքստը, որը հասանելի չէ իր ավագ եղբայրներին: Այնուամենայնիվ, եթե այս կողմերը այնքան էլ տեղին չեն, և արտադրանքը չի տրամադրվել սկաների հետ, ապա հեղինակը մեծ իմաստ չի տեսնում Readiris գնելու մեջ: Քիչ հավանական է, որ այն ավելի լավ թվա, քան, օրինակ, FineReader-ի «sprint» տարբերակը կամ այլ ծրագրի OEM տարբերակը։
OmniPage Pro-ն շատ ավելի հզոր արտադրանք է, որն իր հնարավորություններով մոտ է ABBYY-ի մտահղացմանը (և, ի դեպ, հաջողությամբ մրցակցում է դրա հետ արտասահմանում). այն իրականացնում է նույն ընդլայնված աշխատանքը PDF ֆայլերի հետ, արտահանում գրասենյակային հավելվածներ և XML աջակցություն: . Բացառիկները ներառում են աջակցություն ODMA-ի հետ համատեղելի կորպորատիվ փաստաթղթերի կառավարման համակարգերին, eBook ձևաչափին և բաց OLE ինտերֆեյսի առկայությանը, որը թույլ է տալիս արտադրանքին ինտեգրվել այլ հավելվածների հետ: OmniPage Pro-ի ճանաչված տեքստի աուդիո ընթերցման մեկ այլ առավելություն հազիվ թե գնահատվի ներքին օգտագործողների կողմից, քանի որ ծրագիրը կարող է կարդալ միայն անգլերեն: Ի դեպ, բացակայում է նաև ռուսական ինտերֆեյսը։ Եվ վերջում ուզում եմ առանց մեկնաբանության մեջբերել ապրանքի արժեքը 634 դոլար։
Ամփոփելով՝ կարելի է ասել, որ այսօր ABBYY-ն արժանի մրցակիցներ չունի ռուսական շուկայում՝ գին/որակ հարաբերակցությամբ։ Միգուցե դրանք կհայտնվեն OmniPage-ի տեղայնացումից հետո (ինչպես լեզվի, այնպես էլ գնի առումով): Կյանքը ցույց կտա։
Նյութը տեխնիկական տեսլականից
Ճանաչման առաջադրանք տեքստային տեղեկատվությունտպագիր և ձեռագիր տեքստը թարգմանելիս էլեկտրոնային ձևցանկացած նախագծի կարևորագույն բաղադրիչներից մեկն է, որն ուղղված է աշխատանքային հոսքի ավտոմատացմանը կամ առանց թղթի տեխնոլոգիաների ներդրմանը: Միևնույն ժամանակ, այս առաջադրանքը պատկերների լրիվ ավտոմատ վերլուծության ամենաբարդ և գիտատար խնդիրներից մեկն է։ Նույնիսկ այն անձը, ով կարդում է ձեռագիր տեքստը համատեքստից դուրս, միջինում մոտ $4$(\%) սխալներ է թույլ տալիս: Միևնույն ժամանակ, OCR-ի ամենակարևոր հավելվածներում անհրաժեշտ է ապահովել ավելի բարձր ճանաչման հուսալիություն (ավելի քան 99 (\%), նույնիսկ վատ տպման որակի և սկզբնական տեքստի թվայնացման դեպքում:
Վերջին տասնամյակների ընթացքում համակարգչային տեխնիկայի ժամանակակից առաջընթացի կիրառման շնորհիվ մշակվել են պատկերների մշակման և օրինաչափությունների ճանաչման նոր մեթոդներ, որոնք հնարավորություն են տվել ստեղծել տեքստի ճանաչման արդյունաբերական համակարգեր, ինչպիսին է FineReader-ը, որը բավարարում է աշխատանքային հոսքի ավտոմատացման համակարգերի հիմնական պահանջները: . Այնուամենայնիվ, այս ոլորտում յուրաքանչյուր նոր հավելվածի ստեղծումը դեռևս ստեղծագործական խնդիր է և պահանջում է լրացուցիչ հետազոտություն՝ ելնելով յուրաքանչյուր կոնկրետ առաջադրանքը բնութագրող լուծման, արագության, ճանաչման հուսալիության և հիշողության չափի հատուկ պահանջներից:
Բնորոշ խնդիրներ՝ կապված կերպարների ճանաչման հետ:
Ձեռագիր և տպագիր նիշերի ճանաչման հետ կապված մի շարք էական խնդիրներ կան։ Դրանցից ամենակարեւորները հետեւյալն են.
- կերպարների գրելու մի շարք ձևեր;
- կերպարների պատկերների աղավաղում;
- խորհրդանիշի չափի և մասշտաբի տատանումները:
Յուրաքանչյուր անհատական նիշ կարող է գրվել տարբեր ստանդարտ տառատեսակներով, օրինակ (Times, Gothic, Elite, Courier, Orator), ինչպես նաև բազմաթիվ ոչ ստանդարտ տառատեսակներով, որոնք օգտագործվում են տարբեր առարկայական ոլորտներում: Այս դեպքում տարբեր նշաններ կարող են ունենալ նմանատիպ ուրվագծեր: Օրինակ, «U» և «V», «S» և «5», «Z» և «2», «G» և «6»:
Տեքստի նիշերի թվային պատկերների աղավաղումները կարող են առաջանալ հետևյալի պատճառով.
- տպագրական աղմուկ, մասնավորապես՝ չտպագրություն (շարունակական նիշերի ընդմիջումներ), հարակից նիշերի, բծերի և կեղծ կետերի «կպչում» ֆոնի վրա նիշերի մոտ և այլն.
- նիշերի կամ նիշերի մասերի տեղաշարժը տողի մեջ իրենց ակնկալվող դիրքի համեմատ.
- կերպարների թեքության փոփոխություն;
- «կոպիտ» դիսկրետով պատկերի թվայնացման պատճառով խորհրդանիշի ձևի աղավաղում.
- լուսային էֆեկտներ (ստվերներ, շեշտադրումներ և այլն) տեսախցիկով նկարահանելիս:
Զգալի է նաև բնօրինակ տպագրական սանդղակի ազդեցությունը։ Պայմանական տերմինաբանությամբ՝ $10$, $12$ կամ $17$ սանդղակը նշանակում է, որ $10$, $12$ կամ $17$ նիշերը տեղավորվում են մեկ թիզ տողի մեջ։ Միևնույն ժամանակ, օրինակ, $10$ սանդղակի խորհրդանիշները սովորաբար ավելի մեծ և լայն են, քան $12$ սանդղակի խորհրդանիշը:
Տեքստի օպտիկական ճանաչման (OCR) համակարգը պետք է ընդգծի թվային պատկերի վրա տեքստային տարածքները, ընտրի դրանցում առանձին տողեր, այնուհետև առանձին նիշերը, ճանաչի այդ նիշերը և միևնույն ժամանակ լինի անզգայուն (կայուն) դասավորության տեսակի, հեռավորության նկատմամբ: տողերի և այլ պարամետրերի միջև տպագրություն:
Տեքստի ճանաչման օպտիկական համակարգերի կառուցվածքը:
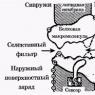
OCR համակարգերը բաղկացած են հետևյալ հիմնական բլոկներից, որոնք ներառում են ապարատային կամ ծրագրային ապահովում.
- տեքստային տարրերի հատվածավորման բլոկ (տեղայնացում և ընտրություն);
- պատկերի նախնական մշակման բլոկ;
- առանձնահատկությունների արդյունահանման միավոր;
- կերպարների ճանաչման միավոր;
- ճանաչման արդյունքների հետմշակման բլոկ:
Այս ալգորիթմական բլոկները համապատասխանում են հաջորդաբար կատարված պատկերի մշակման և վերլուծության հաջորդական քայլերին:
Նախ, ընտրվում է $\textit(տեքստի տարածքներ, տողեր)$, և միացված տեքստային տողերը բաժանվում են առանձին $\textit (նիշերի բացատներ)$, որոնցից յուրաքանչյուրը համապատասխանում է մեկ տեքստային նիշի:
Բաժանվելուց հետո (և երբեմն բաժանումից առաջ կամ ընթացքում), խորհրդանիշները, որոնք ներկայացված են որպես պիքսելների երկչափ մատրիցա, ենթարկվում են հարթեցման, զտման՝ աղմուկը վերացնելու, չափի նորմալացման և այլ փոխակերպումների՝ հետագայում օգտագործվող գեներացնող տարրերը կամ թվային հատկանիշները ընդգծելու համար։ ճանաչել նրանց..
Նիշերի ճանաչումը տեղի է ունենում ընտրված բնութագրական հատկանիշները համեմատելու գործընթացում տեղեկանքային հավաքածուների և հատկանիշների կառուցվածքների հետ, որոնք ձևավորվում և անգիր են անում համակարգը հղման և (կամ) տեքստային նիշերի իրական օրինակների վերապատրաստման գործընթացում:
Վերջնական փուլում իմաստային կամ համատեքստային տեղեկատվությունը կարող է օգտագործվել ինչպես երկիմաստությունները լուծելու համար, որոնք առաջանում են նույն չափսեր ունեցող առանձին նիշերը ճանաչելիս, այնպես էլ սխալ կարդացված բառերն ու նույնիսկ արտահայտությունները ամբողջությամբ ուղղելու համար:
Տեքստային սիմվոլների պատկերների նախնական մշակման և հատվածավորման մեթոդներ:
Նախամշակումը կարևոր քայլ է նիշերի ճանաչման գործընթացում և թույլ է տալիս հարթեցնել, նորմալացնել, բաժանել և մոտավոր գծերի հատվածները:
$\textit(smoothing)$-ն այս դեպքում վերաբերում է պատկերների մշակման ընթացակարգերի մեծ խմբին, որոնցից շատերը քննարկվել են այս գրքի $3$ գլխում: Մասնավորապես, լայնորեն կիրառվում են $\textit(filling)$ և $\textit(thinning)$ ձևաբանական օպերատորները։ $\textit (Լրացնելով)$-ը վերացնում է փոքր ընդմիջումները և բացատները: $\textit(thinning)$-ը գծերի նոսրացման գործընթաց է, որի ժամանակ «բարակ գծի» միայն մեկ պիքսելը քարտեզագրվում է մի քանի պիքսելներից բաղկացած տարածքի յուրաքանչյուր քայլում: Serra-ի ընդլայնման և կծկման օպերատորների վրա հիմնված նման գործողություններ իրականացնելու ձևաբանական ձևը նկարագրված է $3.2$ գլխում:
Այնտեղ նկարագրված է նաև տեքստային նիշերի պատկերների երկուական ֆիլտրման հատուկ ալգորիթմ, որը կոչվում է $\textit( եզրերի ջնջում)$: «Ծոպեր» ասելով այստեղ նկատի ունենք խորհրդանիշի սահմանների անկանոնությունները, որոնք խանգարում են նախ ճիշտ որոշել դրա չափը, երկրորդ՝ աղավաղում են խորհրդանիշի պատկերը և կանխում դրա հետագա ճանաչումը եզրագծային հատկանիշով։
Փաստաթղթերի պատկերների $\textit(Երկրաչափական նորմալացում)$-ը ենթադրում է ալգորիթմների օգտագործում, որոնք վերացնում են առանձին նիշերի, բառերի կամ տողերի թեքություններն ու թեքությունները, ինչպես նաև ներառում են ընթացակարգեր, որոնք նորմալացնում են նիշերի բարձրությունն ու լայնությունը՝ դրանք համապատասխանաբար մշակելուց հետո:
$\textit(segmentation)$ ընթացակարգերը փաստաթղթի պատկերը բաժանում են առանձին շրջանների: Սովորաբար, առաջին քայլը տպագրված տեքստը գրաֆիկական և ձեռագիր գրառումներից առանձնացնելն է: Ավելին, օպտիկական ճանաչման ալգորիթմների մեծ մասը տեքստը բաժանում է նիշերի և ճանաչում դրանք առանձին: Այս պարզ լուծումն իսկապես ամենաարդյունավետն է, քանի դեռ տեքստի նիշերը չեն համընկնում: Նիշերի միաձուլումը կարող է պայմանավորված լինել տառատեսակի տեսակով, որով մուտքագրվել է տեքստը, տպիչի վատ լուծումը կամ բարձր մակարդակպայծառությունն ընտրված է կոտրված նիշերը վերականգնելու համար:
Տեքստի տարածքների և տողերի լրացուցիչ բաժանումը $\textit(words)$-ի օգտակար է, եթե բառը հարուստ օբյեկտ է, ըստ որի կատարվում է տեքստի ճանաչում: Նման մոտեցումը, որտեղ ճանաչման միավորը ոչ թե մեկ նիշ է, այլ մի ամբողջ բառ, դժվար է իրականացնել՝ անգիր անելու և ճանաչվող տարրերի մեծ քանակի պատճառով, սակայն այն կարող է օգտակար և շատ արդյունավետ լինել հատուկ հատուկ դեպքերում, երբ Կոդերի բառարանի բառերի բազմությունը նշանակալի է.սահմանափակվում է խնդրի պայմանով.
$\textit (գծի հատվածների մոտարկում)$-ում մենք հասկանում ենք սիմվոլի նկարագրության գրաֆիկի կազմումը գագաթների և ուղիղ եզրերի մի շարքի տեսքով, որոնք ուղղակիորեն մոտեցնում են բնօրինակ պատկերի պիքսելային շղթաներին: Այս մոտարկումն իրականացվում է տվյալների քանակը նվազեցնելու համար և կարող է օգտագործվել ճանաչման համար՝ հիմնվելով պատկերի երկրաչափությունը և տոպոլոգիան նկարագրող հատկանիշների ընտրության վրա:
Նիշերի առանձնահատկությունները, որոնք օգտագործվում են տեքստի ավտոմատ ճանաչման համար:
Ենթադրվում է, որ առանձնահատկությունների արդյունահանումը օրինաչափությունների ճանաչման ամենադժվար և կարևոր խնդիրներից մեկն է: Նիշերի ճանաչման համար կարող են օգտագործվել մեծ թվով տարբեր հատկանիշների համակարգեր: Խնդիրն այն է, որ ընտրվեն հենց այն հատկանիշները, որոնք արդյունավետորեն կտարբերակեն մեկ դասի սիմվոլները բոլոր մյուսներից այս կոնկրետ առաջադրանքում:
Նիշերի ճանաչման մի շարք հիմնական մեթոդներ և թվային պատկերից հաշվարկված դրանց համապատասխան տեսակները նկարագրված են ստորև:
Համապատասխան պատկերներ և նախշեր:
Մեթոդների այս խումբը հիմնված է թեստային և հղման նշանների պատկերների ուղղակի համեմատության վրա: Այս դեպքում հաշվարկվում է $\textit(նմանության աստիճան)$ պատկերի և յուրաքանչյուր ստանդարտի միջև։ Փորձարկված խորհրդանիշի պատկերի դասակարգումն իրականացվում է մոտակա հարեւանի մեթոդով: Նախկինում մենք արդեն դիտարկել ենք պատկերների համեմատության մեթոդները 4.2 բաժնում, մասնավորապես՝ հարաբերակցության և համապատասխան պատկերների զտման մեթոդները:
Գործնական տեսանկյունից այս մեթոդները հեշտ է իրականացնել, և շատերը կոմերցիոն համակարգեր OCR-ն օգտագործում է դրանք: Այնուամենայնիվ, փոխկապակցման մեթոդների «ճակատային» իրականացման դեպքում, նույնիսկ մի փոքր մուգ բծը, որն ընկել է խորհրդանիշի արտաքին եզրագծի վրա, կարող է զգալիորեն ազդել ճանաչման արդյունքի վրա: Հետևաբար, օրինաչափությունների համապատասխանեցում օգտագործող համակարգերում ճանաչման լավ որակի հասնելու համար օգտագործվում են պատկերների համեմատության այլ, հատուկ մեթոդներ:
Կաղապարների համընկնման ալգորիթմի հիմնական փոփոխություններից մեկը օգտագործում է օրինաչափությունների ներկայացումը որպես տրամաբանական կանոնների մի շարք: Օրինակ, խորհրդանիշը
| 0000000000 |
| 000aabb000 |
| 00aeeffb00 |
| 0ae0000fb0 |
| 0ae0ii0fb0 |
| 0ae0ii0fb0 |
| 0ae0000fb0 |
| 0cg0000hd0 |
| 0cg0jj0hd0 |
| 0cg0jj0hd0 |
| 0cg0000hd0 |
| 00cgghhd00 |
| 000ccdd000 |
| 0000000000 |
կարող է ճանաչվել որպես «null», եթե՝ (առնվազն $5$ «a» նիշերը «1» են կամ առնվազն $4$ նիշ $\text("e") = \text("1")$) AND (ոչ պակաս $5$-ից ավելի «b» նիշերը «1» են կամ առնվազն $4$ նիշ $\text(«f») = \text(«1»)$) AND (առնվազն $5$ «c» նիշերը «1» են կամ առնվազն $4$ նիշ $\text("g") = \text("1")$) AND (առնվազն $5$ նիշերը "d" են "1" կամ առնվազն $4$ նիշ $\text("h" ) = \text("1")$) AND («i» նիշերից առնվազն $3$-ը «0» է) AND («j» նիշերից առնվազն $3$-ը «0» է):
Վիճակագրական բնութագրեր.
Մեթոդների այս խմբում հատկանիշի արդյունահանումն իրականացվում է կետերի տարբեր վիճակագրական բաշխումների վերլուծության հիման վրա։ Այս խմբի ամենահայտնի մեթոդները օգտագործում են $\textit(պահերի հաշվարկ)$ $\textit(և խաչմերուկների քանակը)$։
$\textit (Տարբեր պատվերների պահեր)$-ը հաջողությամբ օգտագործվում է ամենից շատ տարբեր ոլորտներմեքենայական տեսողությունը որպես ձևի նկարագրիչներ ընտրված տարածքների և օբյեկտների համար (տես բաժին 4.1): Տեքստային նիշերի ճանաչման դեպքում «սև» կետերի հավաքածուի մոմենտների արժեքները որոշ ընտրված կենտրոնի համեմատ օգտագործվում են որպես հատկանիշների հավաքածու: Այս տեսակի կիրառություններում առավել հաճախ օգտագործվում են տող առ տող, կենտրոնական և նորմալացված պահերը:
Պահված թվային պատկերի համար երկչափ զանգված$\textit(գծային պահեր)$-ը հետևյալ ձևի յուրաքանչյուր պատկերի կետի կոորդինատների ֆունկցիաներն են՝ $$ m_(pq) =\sum\limits_(x=0)^(M-1) (\sum\limits_ (y=0) ^(N-1) (x^py^qf(x,y))) , $$ որտեղ $p,q \in \(0,1,\ldots ,\infty \)$; $M$-ը և $N$-ը պատկերի հորիզոնական և ուղղահայաց չափերն են, իսկ $f(x,y)$-ը պատկերի $\langle x,y\rangle$-ի պիքսելի պայծառությունն է:
$\textit(Central Moments)$-ը նշանի ծանրության կենտրոնից կետի հեռավորության ֆունկցիան է՝ $$ m_(pq) =\sum\limits_(x=0)^(M-1) (\sum\ limits_(y=0)^ (N-1) ((x-\mathop x\limits^\_)^p(y-\mathop y\limits^\_)^qf(x,y)) ) , $ $ որտեղ $x$ և $ y$ «գծով»՝ ծանրության կենտրոնի կոորդինատները։
$\textit (Նորմալացված կենտրոնական պահեր)$ ստացվում են կենտրոնական մոմենտները զրոյական կարգի մոմենտների բաժանելով։
Պետք է նշել, որ լարային պահերը հակված են ճանաչման ավելի ցածր մակարդակ ապահովելու: Կենտրոնական և նորմալացված պահերն ավելի նախընտրելի են՝ պատկերի փոխակերպումների նկատմամբ նրանց ավելի մեծ անփոփոխության պատճառով:
$\textit (հատման մեթոդ)$-ի առանձնահատկությունները ձևավորվում են հաշվելով, թե քանի անգամ և ինչպես է հատվում խորհրդանիշի պատկերը որոշակի անկյուններում գծված ընտրված գծերի հետ: Այս մեթոդը հաճախ օգտագործվում է առևտրային համակարգերում, քանի որ այն անփոփոխ է կերպարների գրման աղավաղումների և ոճական փոքր տատանումների նկատմամբ, ինչպես նաև ունի բավականին բարձր արագություն և չի պահանջում բարձր հաշվողական ծախսեր: Նկ. 1-ը ցույց է տալիս $R$ նշանի հղման պատկերը, կտրվածքային գծերի համակարգը, ինչպես նաև հղումային վեկտորների հեռավորությունների վեկտորը։ Նկ. 2-ը ցույց է տալիս իրական պատկերի օրինակ
$R$ նշանի հղման պատկերի համար խաչմերուկների մի շարք ձևավորելու օրինակ

$R$ նշանի իրական պատկերի համար խաչմերուկների մի շարք ձևավորելու օրինակ

$R$ նշանի հղման պատկերի համար գոտու նկարագրության ձևավորման օրինակ

$R$ նշանի իրական պատկերի համար գոտու նկարագրության ձևավորման օրինակ; $K = 0(,)387$
նիշ $R$. Գույնը (տես գույնի ներդիր) նշում է նաև մոտակա հարևանին համապատասխանող տողը։
$\textit (Զոնային մեթոդ)$-ը ներառում է շրջանակի տարածքի բաժանում, խորհրդանիշը պարփակելով շրջանների և այնուհետև օգտագործելով տարբեր շրջաններում գտնվող կետերի խտությունը որպես բնորոշ հատկանիշների հավաքածու: Նկ. 3-ը ցույց է տալիս $R$ նշանի հղման պատկերը, իսկ նկ. չորս - իրական պատկեր$R$ նիշ, որը ստացվում է փաստաթղթի պատկերը սկանավորելու միջոցով: Երկու պատկերները ցույց են տալիս գոտիների բաժանումը, յուրաքանչյուր գոտու պիքսելային կշիռները, ինչպես նաև հղումային նշանների հղման վեկտորների հեռավորությունների վեկտորը: Գտնված մոտակա հարեւանին համապատասխանող գիծը նշվում է գույնով։
$\textit(adjacency matrices)$ մեթոդում տարբեր երկրաչափական համակցություններում «սև» և «սպիտակ» տարրերի համատեղ առաջացման հաճախականությունները դիտվում են որպես հատկանիշներ։ $\textit(characteristic-loci)$ (characteristic-loci) մեթոդը որպես հատկանիշ օգտագործում է այն դեպքերի քանակը, երբ ուղղահայաց և հորիզոնական վեկտորները հատում են գծի հատվածները նիշի ֆոնային տարածքի յուրաքանչյուր լուսավոր կետի համար:
Կան նաև այս խմբի բազմաթիվ այլ մեթոդներ:
Ինտեգրալ փոխակերպումներ.
Փոխակերպումների վրա հիմնված ճանաչման ժամանակակից տեխնոլոգիաներից առանձնանում են սիմվոլների Ֆուրիեի նկարագրիչները, ինչպես նաև սահմանների հաճախականության բնութագրիչները օգտագործող մեթոդները։
Ֆուրիե-Մելլինի փոխակերպումներ օգտագործող մեթոդների առավելությունները կապված են այն փաստի հետ, որ դրանք անփոփոխ են մասշտաբի, ռոտացիայի և խորհրդանիշի փոփոխության նկատմամբ: Այս մեթոդների հիմնական թերությունը նրանց անզգայունությունն է սահմաններում պայծառության կտրուկ թռիչքների նկատմամբ, օրինակ՝ դժվար է տարբերակել «O» նշանը «Q» խորհրդանիշից տարածական հաճախականությունների սպեկտրով և այլն։ Միևնույն ժամանակ։ , խորհրդանիշի սահմաններում աղմուկը զտելիս այս հատկությունը կարող է օգտակար լինել:
Կառուցվածքային բաղադրիչների վերլուծություն.
Կառուցվածքային առանձնահատկությունները սովորաբար օգտագործվում են պատկերի ընդհանուր կառուցվածքը ընդգծելու համար: Նրանք նկարագրում են խորհրդանիշի երկրաչափական և տեղաբանական հատկությունները։ Ամենահեշտն է ներկայացնել տեքստային կերպարի կառուցվածքային ճանաչման գաղափարը՝ կապված ավտոմատ ընթերցման խնդրի հետ։ փոստային ինդեքսներ. Նման «շաբլոն» տառատեսակներում յուրաքանչյուր հնարավոր հատված-կտրվածքի դիրքը նախապես հայտնի է, և մի նիշը մյուսից տարբերվում է ոչ պակաս, քան ամբողջ հարվածի առկայությամբ կամ բացակայությամբ։ Նմանատիպ խնդիր է առաջանում պարզ հեղուկ բյուրեղային ցուցիչների մոնիտորինգի դեպքում։ Նման համակարգերում կառուցվածքային բաղադրիչների ընտրությունը կրճատվում է նախկինում հայտնի տրաֆարետի տարրերի վերլուծությամբ (հայտնաբերվող հատվածների մի շարք):
Ավելի բարդ տառատեսակների կառուցվածքային ճանաչման համակարգերում հարվածները հաճախ օգտագործվում են նաև հետևյալը որոշելու համար. բնորոշ հատկանիշներպատկերներ՝ $\textit(վերջնակետեր)$, $\textit(հատվածների հատման կետեր)$, $\textit(փակ օղակներ)$, ինչպես նաև դրանց դիրքը կերպարը պարփակող շրջանակի նկատմամբ։ Դիտարկենք, օրինակ, խորհրդանիշի կառուցվածքային նկարագրության հետևյալ մեթոդը. Թող մաքրված նշանը պարունակող մատրիցը բաժանվի ինը ուղղանկյուն շրջանների ($33$ ցանցի տեսքով), որոնցից յուրաքանչյուրին վերագրվում է «A»–ից «I» տառային ծածկագիրը։ Կերպարը դիտվում է որպես հարվածների մի շարք: Այս դեպքում նիշի ուրվագծի որոշ երկու կետերը միացնող հարվածը կարող է լինել գիծ (L) կամ կոր (C): Կաթվածը համարվում է $\textit(հատված (arc))$ $\textit(կոր)$, եթե դրա կետերը բավարարում են հետևյալ $$ \left| \frac (1)(n) \sum\limits_(i=1)^n \frac (ax_i +by_i +c)(\sqrt(a^2+b^2)) \right| >0(,)69, $$ հակառակ դեպքում այն համարվում է $\textit(ուղիղ հատված)$: Այս բանաձեւում $\langle x_(i),y_(i)\rangle$-ը մի կետ է, որը պատկանում է հարվածին; $ax+by+c=0$ - հարվածի ծայրերով անցնող ուղիղ գծի հավասարումը, էմպիրիկ կերպով ստացվել է $0(,)69$ գործակիցը։ Ավելին, խորհրդանիշը կարելի է նկարագրել իր հատվածների և աղեղների մի շարքով: Օրինակ, \("ALC", "ACD"\) մուտքը նշանակում է, որ կա ուղիղ գիծ, որն անցնում է "A" տարածքից դեպի "C" տարածք, և կոր, որն անցնում է "A" տարածքից դեպի "D" տարածք: համապատասխանաբար.
Կառուցվածքային ճանաչման մեթոդների հիմնական առավելությունը որոշվում է նրանց դիմադրությամբ կերպարի տեղաշարժի, մասշտաբման և փոքր անկյան տակ պտտելու, ինչպես նաև հնարավոր աղավաղումների և ոճի տարբեր տատանումների և տառատեսակի աննշան աղավաղումների նկատմամբ:
Նիշերի դասակարգում.
AT գոյություն ունեցող համակարգեր OCR-ն օգտագործում է $\textit(classification)$-ի մի շարք ալգորիթմներ, այսինքն՝ տարբեր դասերի հատկանիշեր վերագրելով: Դրանք զգալիորեն տարբերվում են՝ կախված ընդունված հատկանիշների հավաքածուներից և դրանց նկատմամբ կիրառվող դասակարգման ռազմավարությունից:
Նիշերի առանձնահատկությունների դասակարգման համար անհրաժեշտ է, առաջին հերթին, ճանաչված նիշերից յուրաքանչյուրի համար ձևավորել հղման հատկանիշի վեկտորների մի շարք: Դա անելու համար $\textit(training)$ փուլում օպերատորը կամ մշակողը մուտքագրում է մեծ թվով նիշերի ուրվագծային նմուշներ OCR համակարգ՝ ուղեկցվող նիշերի արժեքի նշումով: Յուրաքանչյուր նմուշի համար համակարգը հանում է հատկանիշները և պահում դրանք որպես համապատասխան $\textit(հատկանիշի վեկտոր)$: Հատկանիշների վեկտորների հավաքածուն, որը նկարագրում է նիշը, կոչվում է $\textit(class)$ կամ $\textit(կլաստեր)$։
OCR համակարգի գործունեության ընթացքում կարող է անհրաժեշտ լինել ընդլայնել նախկինում ձևավորված գիտելիքների բազան: Այս առումով որոշ համակարգեր ունեն $\textit(լրացուցիչ ուսուցում)$ իրական ժամանակում կատարելու հնարավորություն։
$\textit(դասակարգման ընթացակարգ)$ կամ $\textit(ճանաչում)$-ի խնդիրն է, որն իրականացվում է թեստային նշանի պատկերը համակարգին ներկայացնելու պահին, պետք է որոշել, թե նախկինում ձևավորված դասերից որից է ստացվել հատկանիշի վեկտորը։ տրված նշանը պատկանում է. Դասակարգման ալգորիթմները հիմնված են դիտարկվող նշանի հատկանիշների բազմության դասերի յուրաքանչյուրին մոտիկության աստիճանի որոշման վրա։ Ստացված արդյունքի հավանականությունը կախված է ընտրված հատկանիշի տարածության չափիչից: Տիեզերական հատկանիշի ամենահայտնի չափանիշը ավանդական Էվկլիդեսյան հեռավորությունն է
$$ D_j^E = \sqrt(\sum\limits_(i=1)^N ((F_(ji)^L -F_i^l)^2)), $$ որտեղ $F_(ji)^L$ - $i$-th հատկանիշ $j$-th հղումային վեկտորից; $F_i^l $ - փորձարկվող խորհրդանիշի պատկերի $i$-րդ հատկանիշ:
$\textit(մոտակա հարեւան)$ մեթոդով դասակարգելիս նշան է հատկացվելու այն դասին, որի հատկանիշի վեկտորը ամենամոտն է փորձարկված նիշի հատկանիշի վեկտորին: Պետք է հաշվի առնել, որ նման համակարգերում հաշվողական ծախսերը մեծանում են օգտագործվող հնարավորությունների և դասերի քանակի աճով։
Նմանության չափման բարելավման տեխնիկաներից մեկը հիմնված է հատկանիշների հղման հավաքածուի վիճակագրական վերլուծության վրա: Միևնույն ժամանակ, դասակարգման գործընթացում ավելի հուսալի հատկանիշներին ավելի մեծ առաջնահերթություն է տրվում՝ $$ D_j^E =\sqrt(\sum\limits_(i=1)^N (w_i (F_(ji)^L -F_i^l )^2)) , $$
Որտեղ $w_(i)$-ը $i$th հատկանիշի կշիռն է:
Մեկ այլ դասակարգման տեխնիկա, որը պահանջում է հավանական տեքստի մոդելի մասին a priori տեղեկատվության իմացություն, հիմնված է Բայեսի բանաձևի կիրառման վրա: Բեյսի կանոնից հետևում է, որ դիտարկվող հատկանիշի վեկտորը պատկանում է «$j$» դասին, եթե հավանականության գործակիցը $\lambda $ ավելի մեծ է, քան $j$ դասի նախորդ հավանականության հարաբերակցությունը դասի նախորդ հավանականությանը։ $i$.
Ճանաչման արդյունքների հետմշակում:
Կրիտիկական OCR համակարգերում անհատական նիշերի ճանաչման արդյունքում ձեռք բերված ճանաչման որակը բավարար չի համարվում: Նման համակարգերում անհրաժեշտ է նաև օգտագործել կոնտեքստային տեղեկատվություն։ Համատեքստային տեղեկատվության օգտագործումը թույլ է տալիս ոչ միայն գտնել սխալներ, այլև ուղղել դրանք:
Կան մեծ թվով OCR հավելվածներ, որոնք օգտագործում են գլոբալ և տեղական դիրքային գծապատկերներ, եռագրեր, $n$-գրամներ, բառարաններ և այս բոլոր մեթոդների տարբեր համակցություններ: Դիտարկենք այս խնդրի լուծման երկու մոտեցում՝ $\textit(բառարան)$ և $\textit(երկուական մատրիցների հավաքածու)$՝ մոտավորացնելով բառարանի կառուցվածքը։
Ապացուցված է, որ բառարանային մեթոդներն ամենաարդյունավետներից են առանձին նիշերի դասակարգման սխալները հայտնաբերելու և ուղղելու համար: Այս դեպքում որոշակի բառի բոլոր նիշերը ճանաչելուց հետո բառարանը որոնում են այս բառի որոնման համար՝ հաշվի առնելով այն, որ այն կարող է սխալ պարունակել։ Եթե բառը հայտնաբերվել է բառարանում, դա չի նշանակում, որ սխալներ չկան։ Սխալը կարող է բառարանում գտնվող մի բառը վերածել մեկ այլ բառի, որը նույնպես կա բառարանում: Նման սխալը հնարավոր չէ հայտնաբերել առանց իմաստային համատեքստային տեղեկատվության օգտագործման, միայն այն կարող է հաստատել ուղղագրության ճիշտությունը: Եթե բառը չկա բառարանում, ապա համարվում է, որ բառն ունի ճանաչման սխալ։ Սխալը շտկելու համար նրանք դիմում են նման բառը բառարանից ամենանման բառով փոխարինելու։ Ուղղումը չի կատարվում, եթե բառարանում գտնվեն մի քանի հարմար փոխարինող թեկնածուներ: Այս դեպքում որոշ համակարգերի ինտերֆեյսը թույլ է տալիս օգտատիրոջը ցույց տալ բառը և առաջարկել տարբեր լուծումներ, օրինակ՝ ուղղել սխալը, անտեսել այն և շարունակել աշխատել, կամ ավելացնել այս բառը բառարանում։ Բառարանի օգտագործման հիմնական թերությունն այն է, որ սխալները շտկելու համար օգտագործվող որոնման և համեմատման գործողությունները պահանջում են զգալի հաշվողական ծախսեր, որոնք մեծանում են բառարանի չափի հետ։
Որոշ մշակողներ բառարանի օգտագործման հետ կապված դժվարությունները հաղթահարելու համար փորձում են բառի կառուցվածքի մասին տեղեկատվություն քաղել հենց բառից։ Նման տեղեկատվությունը ցույց է տալիս տեքստում $\textit(n-գրամ)$ (նիշերի հաջորդականություններ, օրինակ՝ տառերի զույգ կամ եռյակ) հավանականության աստիճանը, որը կարող է նաև լինել գլոբալ դիրքով, տեղային դիրքով կամ ընդհանրապես տեղակայված չլինել: Օրինակ, չտեղադրված զույգ տառերի վստահության մակարդակը կարող է ներկայացվել որպես երկուական մատրիցա, որի տարրը հավասար է 1-ի, եթե և միայն այն դեպքում, եթե համապատասխան տառերի զույգը առկա է բառարանում որևէ բառում: Դիրքային երկուական դիագրամը $D_(ij)$-ը երկուական մատրից է, որը որոշում է, թե զույգ տառերից որն ունի ոչ զրոյական հավանականություն $\langle i,j\rangle$ դիրքում հայտնվելու համար։ Բոլոր դիրքային դիագրամների հավաքածուն ներառում է երկուական մատրիցներ յուրաքանչյուր զույգ դիրքի համար:
Ընկերությունը 2007թ
Cognitive Technologies ներկայացված կամ նոր Cognitive Forms 2007 ճանաչման շարժիչը համարIDR - տեխնոլոգիա CogniDocs.գործադիր տնօրեն
Ճանաչողական տեխնոլոգիաներ , Ռուսաստանի գիտությունների ակադեմիայի թղթակից անդամ Վլադիմիր Լվովիչ Արլազարով.IDR-ի գալուստը բնական քայլ էր պատկերների ճանաչման տեխնոլոգիաների զարգացման գործում «նիշերի ճանաչումից մինչև փաստաթղթերի ընկալում»:29.12.2009
Cognitive Technologies-ը վարձավճարով օգտվել է Yandex-ինշարահյուսական անալիզատոր , որը թույլ է տալիս որոշել, թե ինչ շարահյուսական հարաբերությունների հետ են կապված նախադասության բառերը։ Տեքստային մեծ կորպուսների համար դրա օգտագործումը թույլ է տալիս որոշել և ուսումնասիրել լեզվի վիճակագրական օրինաչափությունները (բառերի և կոնստրուկցիաների առաջացումը) երկիմաստությունները լուծելիս (օրինակ՝ «բանալին ընկավ հատակին» և «բանալին մուրճը քարերի մեջ էր»): որոնք առաջանում են շարահյուսական վերլուծության ժամանակ, ինչպես նաև խոսքի շարունակական ճանաչման համար վիճակագրական լեզվական մոդելներ կառուցելիս։ԻՑ վերլուծիչ թույլ է տալիս համեմատել տեքստերը՝ հիմնված դրանցում տարբեր բառերի և կառուցվածքների առկայության վրա և մշակել տեքստեր հասկանալու, տեքստերից տվյալներ հանելու, ինչպես նաև այլ հավելվածների մեթոդներ:
Հիմնված
վերլուծիչ Cognitive Technologies-ը ստեղծել է մի շարք խելացի ծրագրային արտադրանք, ինչպիսիք են հեղինակության և փաստաթղթերի ոճը որոշելու համակարգեր:29.12.2009
Ճանաչողական տեխնոլոգիաներցույց է տվել «կատվին շանից տարբերելու» դասական խնդիրը լուծելու կարողությունը։1967 թ., հայտնի խորհրդային կիբեռնետ Միխայիլ Մոիսեևիչ Բոնգարդ հրատարակել է «Ճանաչման խնդիրներ» գիրքը », նվիրված օրինաչափությունների ճանաչման տեսության խնդիրներին։Այն պարունակում էր «Խնդիր ճանաչող ծրագրի համար»՝ հարյուրավոր ճանաչման առաջադրանքների ցանկ («Բոնգարդի թեստեր»), որոնք հեշտությամբ լուծվում են մարդու կողմից, բայց չունեն ալգորիթմի տեսքով դրանց նկարագրության հստակ չափանիշներ։ Այդ խնդիրներից մեկը «կատվին շանից տարբերելն էր», խնդիր, որը ցանկացած երեխա, նույնիսկ խոսել դեռ չսովորած, լուծում է կես հայացքով։ Եթե ցանկանում եք խաղալ այս թեմայի շուրջ հարցերով և պատասխաններով, ապա արագ կհայտնաբերեք, որ կատուներին (կամ, ընդհակառակը, շներին) բնորոշ ցանկացած հատկանիշ չի կարող բոլոր դեպքերում տարբերության միանշանակ և հարյուր տոկոս չափանիշ ծառայել: Շարժվող ճանկեր. Կատուն կարող է դրանք բաց թողնել ցանկացած պահի, բայց դրանից մենք չենք շփոթի այն շան հետ։ Ուղղահայաց աշակերտ? Մենք նաև հեշտությամբ տարբերում ենք փակ աչքերով կատվին։ Եվ այսպես շարունակ։ |
Cognitive-ի ներկայացուցիչները բոլորին հրավիրեցին նախապես ֆլեշ կրիչներով բերել կատուների և շների պատկերներ, և նրանք ցուցադրեցին ծրագրի աշխատանքը հյուրանոցի նախասրահում տեղադրված համակարգչի վրա, որտեղ անցկացվում էր ասուլիսը։ Ոչ մի սխալ թույլ չի տրվել. հաղորդումը վստահորեն (30:8 հարաբերակցությամբ) նույնացրել է շանը նույնիսկ բրդոտ Շպիցի լուսանկարում:
Այս ցուցադրությունը, ըստ ընկերության ներկայացուցիչների, ընդամենը պատկերների դասակարգման ընդհանուր խնդրի լուծման օրինակ էր։ Առայժմ բավարար ծրագրեր չկան գործնական կիրառությունԱյս տեսակի նույնիսկ ամենապարզ առաջադրանքները վստահորեն լուծելով՝ օրինակ՝ ընտրել բոլոր կանացի դիմանկարները որոշակի պատկերասրահից, կամ նույնիսկ ավելի հեշտ՝ գտնել միայն բնանկարներ բոլոր նկարներից:
Բոլոր իսկապես աշխատող պատկերների որոնման և դասակարգման համակարգերը կրճատվում են հիմնականում տեքստի համատեքստի վերլուծությամբ (ինչպես Google-ի որոնումնկարներից), և եթե նրանք փորձում են ինչ-որ բան ճանաչել (
դեմքի որոնում, Exalead և այլք), այնուհետև՝ ըստ խիստ սահմանափակ չափանիշների և արդյունքների ակնհայտորեն անբավարար համապատասխանությամբ: Նույնիսկ նույն պատկերի կրկնօրինակների տարրական որոնման համակարգերը հաճախ են սայթաքում պարզ փոփոխություննկարները կտրելիս կողմի հարաբերակցությունը: Իսկ այն ֆիասկոյի մասին, որ կրել են հսկողության տեսախցիկներից ստացված պատկերներից հետախուզվողներին նույնականացնելու համակարգերը (ինչպես երբեմնի հայտնի ծրագիրը FaceIT), մամուլը բազմիցս գրել է։Դժվար է գերագնահատել պատկերների ճանաչման ընդհանուր տեխնիկա գտնելու և դրանք տվյալ դասերից որևէ մեկին վերագրելու հետևանքները։ Սա հեղափոխություն է ոչ միայն համացանցում սովորական պատկերների որոնման, այլ նաև դատաբժշկական, գիտական կիրառությունների (աշխարհագրական տեղեկատվական համակարգերում, կենսաբանության, բժշկության մեջ) և ռազմական ոլորտում: Այսպիսով, մեզ մնում է միայն հաջողություն մաղթել ընկերությանն այս ուղղությամբ: Բայց միևնույն ժամանակ, արժե զգուշացնել անհիմն լավատեսությունից. ինչպես գիտեք, մեքենայական լեզվով թարգմանության խնդիրը գրեթե լուծված էր համարվում կես դար առաջ։ Իսկ թե ինչպես է այն գործում մինչ օրս գործնականում, մենք բոլորս լավ գիտենք…
Տեքստի ճանաչման համակարգեր (OCR համակարգեր)
| Պարամետրի անվանումը | Իմաստը |
| Հոդվածի թեման. | Տեքստի ճանաչման համակարգեր (OCR համակարգեր) |
| Ռուբրիկա (թեմատիկ կատեգորիա) | Տեխնոլոգիա |
Ընդհանուր բնութագրեր և ֆունկցիոնալություն Adobe ծրագրակազմֆոտոշոփ
ֆոտոշոփծրագիր է պրոֆեսիոնալ դիզայներների և բոլոր նրանց համար, ովքեր ներգրավված են գրաֆիկական պատկերների մշակման մեջ: Այն թույլ է տալիս մշակել և ուղղել համակարգիչ մուտքագրված պատկերները արտաքին աղբյուրներից (սկաներ, թվային տեսախցիկ կամ թվային տեսախցիկ), ᴛ.ᴇ: աշխատում է ռաստերային (թվայնացված) գրաֆիկայով։
PhotoShop-ն ունի բազմաթիվ պատրաստի հավելումներ հատուկ էֆեկտներ ստեղծելու համար, ինչպես նաև պատկերը ձեռքով կարգավորելու լավագույն գործիքները:
Photoshop-ի հիմնական հատկանիշներն են.
1. Բազմաշերտ պատկեր ստեղծելու հնարավորություն, մինչդեռ յուրաքանչյուր շերտ կարելի է խմբագրել առանձին և տեղափոխել այլ շերտերի համեմատ: Վերջնական պատկերը կարող է պահպանվել և՛ ʼʼʼʼʼʼ ձևով (PSD ձևաչափով), և՛ բոլոր շերտերը կարող եք միաձուլել մեկի մեջ՝ վերածելով դրանցից մեկի: ստանդարտ ձևաչափեր(JPG, GIF և այլն)
2. Գույների հետ աշխատելու լայն հնարավորություններ. աշխատել տարբեր գունային ռեժիմների հետ (օրինակ, նկարը կարող եք դիտել և խմբագրել ինչպես RGB, այնպես էլ CMYK ռեժիմներում); Գույների լավագույն ճշգրտման գործիքների առկայությունը (և յուրաքանչյուր գույնի պարամետրերը կարող են ճշգրտվել առանձին):
3. Ներկառուցված վեկտորի խմբագրման հնարավորություններ:
4. Պատկերի ուրվագծերը գծելու և կտրելու մի քանի տասնյակ գործիքների առկայությունը, ինչպես նաև. պրոֆեսիոնալ գործիքներպատկերի առանձին հատվածներ ընտրելու և խմբագրելու համար:
5. Պատկերների համադրման և հյուսվածքների հետ աշխատելու ամենահարուստ հնարավորությունները։
6. Զտիչների և հատուկ էֆեկտների բազմազանության առկայությունը (պարզներից, որոնք թույլ են տալիս կարգավորել պատկերի հստակությունը, մինչև շատ էկզոտիկ, որոնք թույլ են տալիս ստեղծել եռաչափ ծավալային առարկաներ երկչափ լուսանկարներից, նմանակել պայթյունների, ծխախոտի ծխի և այլնի հետևանքները), լրացուցիչ plug-ins միացնելու ունակությունը:
7.Support տասնյակ ֆայլեր գրաֆիկական ծրագրեր, բնիկ ֆայլի ձևաչափ, որը տարածված է IBM PC և Mac պլատֆորմների համար:
8. Տեքստի հետ աշխատելու գործիքների առկայություն, պատկերի ցանկացած մասում (նկարի վրայով) տեքստ ավելացնելու հնարավորություն, տեքստի ձևը փոխելու և այլն։
9. Կատարված փոփոխությունների բազմափուլ չեղարկման հնարավորություն (օգտագործելով հատուկ վահանակ՝ «Պատմություն»)։
Ցանկացած սկանավորված տեղեկատվություն գրաֆիկական ֆայլ է (նկար): Հետևաբար, սկանավորված տեքստը չի կարող խմբագրվել առանց հատուկ թարգմանության տեքստի ձևաչափ. Այս թարգմանությունը կարելի է անել Նիշերի օպտիկական ճանաչման (OCR) համակարգեր:
Տպագիր փաստաթղթի էլեկտրոնային (խմբագրման պատրաստ) պատճեն ստանալու համար OCR ծրագիրՉափազանց կարևոր է կատարել մի շարք գործողություններ, որոնցից են հետևյալները.
1. Սեգմենտացիան- սկաներից ստացված «պատկերը» բաժանված է հատվածների (տեքստն առանձնացված է գրաֆիկայից, աղյուսակի բջիջները՝ առանձին մասերի և այլն):
2. Ճանաչում- տեքստը գրաֆիկական ձևից վերածվում է սովորական տեքստի:
3. Ուղղագրության ստուգում և խմբագրում -ներքին ուղղագրության ստուգիչը ստուգում և ուղղում է ճանաչման համակարգի աշխատանքը (վիճելի բառերն ու նիշերը ընդգծված են գունավոր, օգտագործողը տեղեկացվում է «անորոշ ճանաչված նիշերի» մասին)
4. Պահպանում- ճանաչված փաստաթուղթ գրել անհրաժեշտ ձևաչափի ֆայլում՝ համապատասխան ծրագրում հետագա խմբագրման համար:
Վերը թվարկված գործողությունները OCR համակարգերի մեծ մասում կարող են կատարվել ինչպես ավտոմատ կերպով (օգտագործելով կախարդական ծրագիր), այնպես էլ ձեռքով (առանձին):
Ժամանակակից OCR համակարգերը ճանաչում են տեքստերը տարբեր տառատեսակներով; ճիշտ աշխատել մի քանի լեզուներով բառեր պարունակող տեքստերի հետ. ճանաչել աղյուսակները և թվերը; թույլ է տալիս արդյունքը պահպանել տեքստային ֆայլում կամ աղյուսակային ձևաչափովև այլն։
OCR համակարգերի օրինակներ են՝ CuneiForm-ը Cognitive-ից և FineReader-ը ABBYY Software-ից:
OCR համակարգ FineReaderթողարկված տարբեր տարբերակներ(Սպրինտ, Գլխավոր հրատարակություն, Professional Edition, Corporate Edition, Office) և բոլորը, ամենապարզից մինչև ամենահզորը, ունեն շատ օգտագործողի համար հարմար ինտերֆեյս, և նաև (կախված փոփոխությունից) ունեն մի շարք առավելություններ, որոնք տարբերում են դրանք նմանատիպ ծրագրերից։
Օրինակ, FineReader Professional Edition-ը (FineReader Pro) ունի հետևյալը ֆունկցիոնալությունը:
§ աջակցում է գրեթե երկու հարյուր լեզուների (նույնիսկ հնագույն լեզուներ և ծրագրավորման հայտնի լեզուներ);
§ ճանաչում է գրաֆիկական պատկերներ, աղյուսակներ, փաստաթղթեր բլանկների վրա և այլն;
§ լիովին պահպանում է փաստաթղթերի ձևաչափման և դրանց գրաֆիկական ձևավորման բոլոր առանձնահատկությունները.
§ տեքստերի համար, որոնցում օգտագործվում են դեկորատիվ տառատեսակներ կամ օգտագործվում են հատուկ նիշեր (օրինակ՝ մաթեմատիկական), տրամադրվում է «Ճանաչում ուսուցման հետ» ռեժիմը, որի արդյունքում ստեղծվում է տեքստում հայտնաբերված նիշերի ստանդարտ՝ հետագա ճանաչման համար։ ;
Տեքստի ճանաչման համակարգեր (OCR համակարգեր) - հայեցակարգ և տեսակներ: «Տեքստի ճանաչման համակարգեր (OCR համակարգեր)» կատեգորիայի դասակարգումը և առանձնահատկությունները 2017, 2018 թ.
Ցանկացած ժամանակակից մարդ, անընդհատ աշխատելով փաստաթղթերի հետ, ժամանակ առ ժամանակ ինքն իրեն արդիական հարց է տալիս՝ ինչո՞ւ նորից տպել տեքստը, եթե ինչ-որ մեկն արդեն դա արել է նախկինում: Շատ օգտատերերի համար նման կրկնվող առաջադրանքը վրդովմունքի խառնուրդ է առաջացնում ուրիշի աշխատանքը անիմաստ կրկնօրինակելու համար: Բնականաբար, ծրագրային ապահովման մշակողները չէին կարող անտարբեր մնալ նման բնորոշ իրավիճակի նկատմամբ, որի վերացումը, առավել եւս, խոստանում էր ամուր շահույթ։ Այսպես են Ռուսաստանում հայտնի համակարգերը OCR համակարգեր, իսկ անգլիախոս երկրներում՝ ինչպես OCR.
Այսօր OCR ծրագրային ապահովման շրջանակը զգալիորեն ընդլայնվել է. սկզբում այն օգտագործվում էր հիմնականում ֆինանսական և բանկային ոլորտում՝ լուծելով անձնական և հետազոտական տվյալների մուտքագրման հատուկ ավտոմատացման խնդիրներ, բայց այսօր OCR ծրագրերն արդեն օգտագործվում են ամենուր՝ ցանկացած փաստաթղթի հետ աշխատելու համար: Դժվար է գերագնահատել OCR համակարգերի նշանակությունը, որոնք դարձել են այնքան անհրաժեշտ ծրագրակազմ ինչպես գրասենյակային, այնպես էլ տնային համակարգիչների համար:
Եկեք համառոտ անցնենք բոլորին հիմնական OCR համակարգերը շուկայումեւ առանձնացնել նրանց համար հիմնական եւ բնորոշ հատկանիշները։
Նախքան OCR համակարգերի քննարկումը սկսելը, եկեք նախ տանք դրանց գոնե նվազագույն դասակարգումը հետագա քննարկման հարմարության համար: Ներկայումս հատկացնել OCR համակարգեր (օպտիկական բնույթի ճանաչում, OCR) և նաև ICR համակարգեր(Խելացի կերպարների ճանաչում, ICR): Որոշակիորեն պարզեցնելով դրանց միջև եղած տարբերությունների էությունը, մենք կարող ենք ենթադրել, որ ICR համակարգերը հաջորդ սերունդն են OCR համակարգերի զարգացման մեջ: ICR-ն շատ ավելի ակտիվ և լրջորեն օգտագործում է արհեստական բանականության հնարավորությունները, մասնավորապես, ICR համակարգերը հաճախ օգտագործվում են ճանաչելու համար: ձեռագիր տեքստեր, դեկորատիվ ոչ մշտական տառատեսակներ, ինչպես նաև որպես ամենավառ օրինակ՝ հաղթահարելով սպամ բոտերից պաշտպանվելու նույն համակարգերը՝ captcha ( captcha) Տեքստի ճանաչման որակի երրորդ, առայժմ միայն տեսական մակարդակն է IWR(Խելացի բառերի ճանաչում, IWR), որտեղ կարդացվում և ճանաչվում են ոչ թե առանձին նիշեր/կետեր, այլ ամբողջ կապակցված արտահայտությունները կարդացվում և ճանաչվում են:
Կան մի քանի համակարգեր, որոնք իրենց դասակարգում են որպես ICR: Սա առաջին հերթին , FineReader, OmniPage Professional, Readiris Corporate, Type Reader Desktop:Եկեք համեմատենք բոլորին և դիտարկենք հնարավոր այլընտրանքները:
Հատկանշական հայրենական արտադրանք
արտասահմանյան արտադրանք
Երեք այլ հայտնի ապրանքներ, որոնք քիչ տարածում են ստացել ԱՊՀ-ում՝ ներկայացուցիչների իսպառ բացակայության և այս անվերջ կիրիլյան տարածքներում քիչ շուկայավարման պատճառով, բայց հայտնի են Արևմուտքում և արժանի են գոնե հակիրճ հիշատակման, թեկուզ միայն այն պատճառով, որ դրանք նույնպես դիրք են զբաղեցնում։ իրենք՝ որպես ICR դասի արտադրանք: Ոչ կիրիլյան ճանաչման խորշում նրանք կարող են մրցակցել նույնիսկ շուկայի առաջատարի՝ FineReader-ի հետ:
Դրանցից առաջինը փաթեթ է I.R.I.S. Group, շատ լուրջ OCR արտադրանք է: Բավական է նշել, որ 2006 թվականի սեպտեմբերից տեխնոլոգիան I .R .I .S. լիցենզավորված է և օգտագործվում է Adobe համակարգերի արտադրանքներում: Ինքը՝ Adobe-ի ներքին փորձարկումների համաձայն, այս տեխնոլոգիան ամենահաջողն է եղել շուկայում դիտարկվածներից:
Հարկ է նշել, որ երրորդ կողմի այս հաջող լուծումը «թաղեց» իր սեփական զարգացում Adobe-ի բնիկ OCR շարժիչը երկար տարիներ առաքվել է որպես լուծման մաս, և այժմ Adobe-ի նոր OCR-ը հասանելի է որպես անկախ այլ հայտնի Acrobat արտադրանքներում: Վերջին տարբերակը Readiris v12-ն աջակցում է Windows-ի և MacOS X-ի բոլոր տարբերակները և աջակցվում է ավելի քան 120 լեզուներով:

Ամերիկյան ընկերության հաջորդ խոշոր զարգացումը . Այս շարժիչը մշակվել է Լաս Վեգասի Նևադայի համալսարանի հետ սերտ համագործակցությամբ: Այս շարժիչը միանգամից տարածվում է աշխարհով մեկ՝ սկսած այն ինտեգրվելով արևմտյան փաստաթղթերի կառավարման խոշոր համակարգերին (D ocument Imaging Management, DIM) և ավարտվում է ամերիկյան ձևերի ավտոմատ մշակման բազմաթիվ ծրագրերի մասնակցությամբ (Forms P rocessing Services, FPS):
Օրինակ՝ թերթը 2008թ Լոս Անջելես ԹայմսԱշխարհի առաջատար OCR-ի սեփական փորձարկումից հետո նա ընտրեց TypeReader-ն իր ներքին օգտագործման համար: Ցանկանում եմ նշել, որ այս ապրանքը հասանելի է և՛ աշխատասեղանի ավանդական տարբերակով (Windows, MacOS, Linux), որպես կորպորատիվ վեբ ծառայություն և որպես ամպի վրա հիմնված վարձակալության ծրագիր, որը կարող է շատ կարճ ժամանակում մշակել ցանկացած քանակությամբ ճանաչելի տեքստ: ժամանակ.

Անվճար OCR լուծումներ
Google-ը նաև մշակում է հետաքրքիր սեփական շարժիչ: ի սկզբանե փակ առևտրային OCR շարժիչ է, որը ստեղծվել է Hewlett-Packard-ի կողմից 1985-1995 թվականներին: Բայց այն բանից հետո, երբ նախագիծը փակվեց և դրա զարգացումը դադարեց, 2005 թվականին HP-ն թողարկեց իր ծածկագիրը որպես բաց կոդով։ Զարգացումը անմիջապես ընդունվեց Google-ի կողմից՝ արդեն լիցենզավորելով իր արտադրանքը անվճար Apache լիցենզիայի ներքո: Այս պահին Tesseract-ը համարվում է գոյություն ունեցող ամենաճշգրիտ և որակյալ անվճար շարժիչներից մեկը։
Միևնույն ժամանակ, պետք է հստակ հասկանալ, որ Tesseract-ը դասական OCR է «հում» տեքստի մշակման համար, այսինքն. այն չունի գրաֆիկական պատյան հարմար հսկողությունգործընթաց, ոչ էլ շատ ուրիշներ լրացուցիչ հնարավորություններ. Սա սովորական կոնսոլային ծրագիր է (կան Windows-ի, MacOS-ի, Linux-ի տարբերակներ), որը որպես մուտքագրում ստանում է պատկեր TIFF ձևաչափով, իսկ Tesseract-ը թողարկում է «պարզ տեքստ» որպես ելք: Այնուամենայնիվ, այստեղ տեքստի դասավորության կամ դիզայնի ոճերի վերլուծություն չի կատարվում, սա ճանաչման գործընթաց է իր ամենապարզ ձևով:

Ավելի մեծ հարմարության համար, որպես գրաֆիկական ճակատ, այս շարժիչով կարող են օգտագործվել բազմաթիվ կոմունալ ծառայություններ, օրինակ՝ հայտնի կամ. Այնուամենայնիվ, ես կցանկանայի նշել, որ անվճար C uneiForm / OpenOCR-ի որակը փոքր-ինչ գերազանցում է Tesseract-ին, չնայած շատ առումներով դրանք լիովին նման ապրանքներ են:
Բացի անվճար Tesseract-ից, հարկ է նաև նշել. SimpleOCR-ը շատ պարկեշտ OCR լուծում է, և չնայած այն չի մշակվել 2008 թվականից ի վեր, այն առնվազն նույնքան լավն է, որքան Tesseract-ը: Ապրանքը անվճար է ցանկացած ոչ առևտրային օգտագործման համար և հասանելի է Windows-ի բոլոր տարբերակների համար: Ուժեղ մինուսներից՝ միայն երկու լեզուների աջակցություն՝ անգլերեն և ֆրանսերեն:

Բացի աշխատասեղանի ավանդական անվճար լուծումներից, կան բազմաթիվ այլընտրանքային առցանց ծառայություններ, որոնք առաջարկում են անվճար OCR ճանաչման որակ, որը զգալիորեն ցածր է իրենց առևտրային գործընկերներից: Բիզնեսի խնդիրները (և առօրյա այլ լուրջ խնդիրներ) հաջողությամբ լուծելու համար ավելի լավ է կենտրոնանալ ICR դասի առևտրային համակարգերի վրա, որոնք քննարկվել են այս հոդվածի առաջին կեսում: